
- 1. Companies in regulated industries — such as pharmaceutical, financial and logistics, can utilize Data Lakes to improve the agility of data processing and become data driven. But it is crucial for these organizations to stay compliant with industry regulations and at the same time to not slow down the development of their data capabilities.
- 2. No structure, no limits
- 3. Regulatory requirements entail:
- 4. 1. Declarative configuration
- 5. 2. Microservices: smooth control
Companies in regulated industries — such as pharmaceutical, financial and logistics, can utilize Data Lakes to improve the agility of data processing and become data driven. But it is crucial for these organizations to stay compliant with industry regulations and at the same time to not slow down the development of their data capabilities.
This, of course, can be done.
The agile approach assumes we are unable to predict future needs, so it is difficult to write rules for the future. Accordingly, the Data Lake contains data waiting for the right moment to become useful. That data is raw, and not modeled or integrated. It becomes structured as soon as a well-defined query arises.
This provides many benefits, but you need a special approach to leverage them. Especially when you are in a regulated industry, such as finance, pharma, or transport and logistics.
No structure, no limits
The Data Lake environment can accept any number of raw files without the need to structure them, without affecting the existing infrastructure. It does not set limits and does not force you to define the structure while writing. Instead, by collecting raw data, a Data Lake allows it to be modelled while being read. And due to the high scalability achieved in this way, Data Lakes open the way to analytics based on large amounts of data.
A Data Lake is not a tool, nor a specific solution or product that a company can buy, install, and use. As a reference architecture, it is an organization’s mode of approach to using data in its operations, and involves:
- Data governance: defining organizational structures, data owners, policies, rules, processes, business terms and metrics throughout the data lifecycle.
- Data management: implementation of data governance rulesets throughout the whole lifecycle of data, from creation to retirement.
Can such an agile, unstructured repository filled with raw data be used in regulated industries? What about the risk of breaching compliance with strict formal requirements and restrictions that, like in the pharmaceutical industry, define processes of drug research and pharmaceutical product development, manufacturing with quality control, drug registration, distribution and even marketing?
The answer is yes, it can, if the data governance principles are well-designed and implemented. Only a well-governed Data Lake can minimize the risk and cost of non-compliance, legal complications, and security breaches.
Regulatory requirements entail:
- Testing each element with regard to detailed formal procedures
- Thorough analysis and repair of each encountered error
- Formalizing of installation processes and other database maintenance processes
- Validation of any IT tools used
Working with the leaders of the pharmaceutical industry, we have developed a method of implementing Data Lakes in a way that allows you to control data while maintaining its agility. Let me share the two most important elements of that method below.
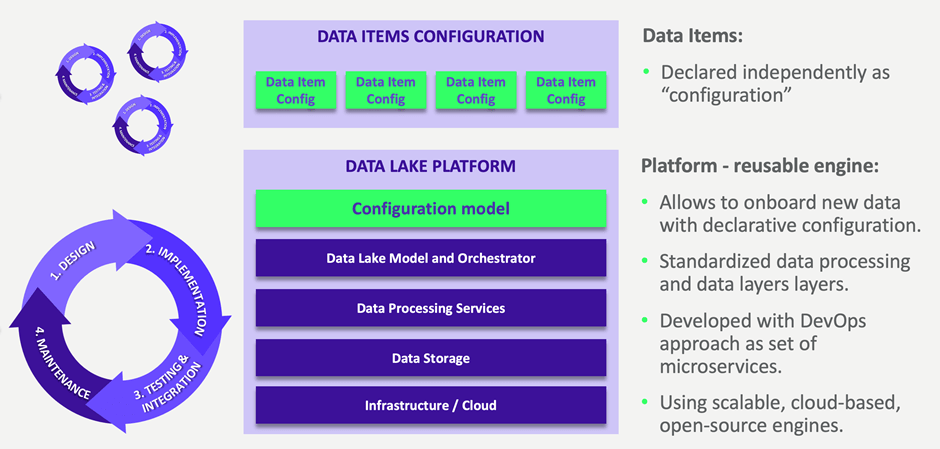
1. Declarative configuration
This feature maintains the open nature of the Data Lake, while extracting its common functionalities. Further declarative configuration is simple and facilitates the work of analysts, data engineers and other advanced users who can draw reliable insights from huge amounts of data. There is no rigid architecture, but instead small services regulating the inflows and outflows of the lake.
2. Microservices: smooth control
Our experience is that control in a Data Lake can be achieved by establishing the underlying principles and using microservices to organize the whole system of dispersed rules. It’s microservices that make up the Data Lake engine and are the key to reconciling the two approaches (data openness and data regulation). They are configurable, the process of their implementation is simplified, and we can adjust their content to the formal requirements.
How does the microservice approach solve the strict regulation problem?
- Dividing into components allows for single validation and then multiple use.
- Isolation of central services enables adding new data items as configuration items that are not strictly regulated.
- Microservices are loosely coupled, which means they evolve independently — they can be scaled individually. By precisely marking their boundaries, testing becomes simpler, faster, and safer.
A highly regulated operating environment requires companies to be cautious about innovation. But organizations are effectively transforming towards data-driven decision making. While in this process the technology is secondary, the most important thing is proper architecture and its execution. Success in this area means the ability to achieve new business goals and increase competitiveness, as well as a greater opening of the organization to further technological advancements, such as the cloud and machine learning. And all this while maintaining compliance. This requires the kind of agility provided by the compliant Data Lake approach.
Would you like more information about this topic?
Complete the form below.