This article explores the process of migrating data from legacy systems to Microsoft Dataverse, offering practical insights against challenges. The main purpose of this article is to present our approach and practices which in our case ensured a smooth transition in data migration project.
The main business goals of the project included:
- Migrating data to Microsoft Dataverse Application
- Reducing as much as possible downtime of an application (two separate applications couldn’t work in parallel)
- Ensuring high quality of data
The Nature of Data
The data migration involved five tables, encompassing up to 500,000 records in total, along with the relationships between records. Tables included Accounts, Shifts, Shift Orders, Jobs, and Providers. Additionally, there was a relationship table between Providers and Accounts, which calculated the distance between points.
The dataset was dynamic, with several thousand records being updated or added each day. These continuous changes required careful planning to ensure that the data migration process captures the most current information. It was crucial to implement a strategy that accommodates these daily changes to maintain the integrity and accuracy of the migrated data.
Applied Strategy
Our strategy centered around detecting new, modified or deleted records between Application data snapshots. We could only retrieve full snapshots of data from the legacy application, which made the process more difficult. An entire logic comparing records from different data dumps was built on top of dbt modeling. Additionally, we implemented validation logic to prevent sending faulty data to the final destination—Dataverse. This eliminated, among others, relations that would be not possible, due to missing lookups records.
What is Microsoft Dataverse?
Microsoft Dataverse is a cloud-based, low-code data platform that serves as a robust and dynamic solution for businesses to manage and store their data. It was selected or this projects, since it offers immense scalability and state-of-the-art security features and is designed to be a prime data repository for business-oriented data.
Challenges Related to the Migration to Dataverse
During the migration to the new environment, the entire application had to be disabled. Because of that, it was crucial to execute the migration as quickly as possible. Every minute of downtime translated into financial loss for the client, and difficulties for the app’s users. In order to speed up transport of data from the source system to Dataverse, we had to resolve to the following challenges:
- Long duration of integrating data into Dataverse – data on Dataverse is being fed to Power Apps applications, Power BI dashboards and other tools from the Power Platform ecosystem. This data must always be of high quality and accuracy. It requires meticulous validation of every new or modified row sent to Dataverse. Moreover, Dataverse enriches data with additional columns containing metadata. New rows are indexed and connected to other tables by relations. Because of these factors, adding data to such a controlled environment takes significantly more time than an SQL insert query on a regular relational database.
- Limitations of the environment – Dataverse is protected from overloading the environment, by imposing various limits. Their purpose is to “help ensure service levels, availability, and quality”. These limits restrict access to Dataverse not only directly through its API, but also through Power Platform tools such as Dataflows. There are two categories of Dataverse limits, which have to be taken into account:
- Service protection limits – they protect Dataverse from unexpected surges of activity in short time windows. They count incoming requests in a 5-minute moving window and reject those exceeding the allowed quota. Our migration tool had to be able to react to errors related to those limits and wait the right amount of time to let the Dataverse environment cool off.
- Entitlement limits – they represent the number of requests users are entitled to make each day. To respect this limit, we had to design a flow, which would process and transport all data with as few requests as possible, avoiding unnecessary actions on Dataverse and performing most of transformations during the pre-processing stage.
- Plugin error handling – the Dataverse environment which was the target of the migration, had a lot of active plugins and automatic flows executing additional logic on various triggers. Two examples of such triggers are adding a new row to a table or modifying an existing one. Some of those plugins, especially ones performing I/O operations on external databases, frequently failed. When it happened, Dataverse cancelled the transaction related to the new or modified row and the process had to be repeated. Because of that, it was important to design a robust migration solution with effective error handling based on a retry system and on logging of unexpected failures.
- Moving the plugin logic out of Dataverse – besides the I/O plugins described above, there were also flows with the purpose of enriching data on Dataverse. When a new row was added to one table, these flows used it to populate other tables or to add more details to existing data. Such flows and plugins took a long time to execute and they were susceptible to API throttling caused by too many requests being sent. There were two especially time-consuming flows, which automatically calculated distances between addresses. These flows created millions of rows. When executed on Dataverse, this took hours to finish. To speed up the migration and to reduce downtime of the application, we focused on identifying the slowest plugins, which could be deactivated during the migration and activated only afterwards, or whose logic could be moved outside of Dataverse to, e.g., a relational database.
- Automation of the migration – The planned migration solution consisted of steps involving multiple separate tools and systems. Dependencies between those steps formed a sequential flow. To additionally optimize the process, we decided to execute some steps in parallel. It would be slow and error-prone to carry out the migration manually, which is why it was pivotal to automate the flow’s execution and to model all dependencies programmatically.
Our Approach
In this section, we will provide a comprehensive overview of all the steps required to successfully complete the entire migration process. Below, you will find a detailed examination of the migration process from the data perspective.
- Load data from the legacy application
We received files in .csv format which were loaded to a staging database – In our case it was an Azure SQL database. This data was loaded by the Microsoft’s Bulk Copy Program (BCP)— we’ll provide a more detailed explanation in the technical section.
- Transformation of data
- Typing all of the input data:
- Ensures the migrated data is accurately captured and correctly formatted.
- Lays a solid foundation for the entire migration process.
- Process of catching failing records (Elimination of duplicates, identifying records which could cause issues during API calls):
- Maintains data integrity and prevents migration errors.
- Ensures that problematic records are captured and potentially fixed during the next delta loading or fixed manually right after the final migration.
- Calculating delta records (determine Upserts and Deletes):
- Ensures that initial load includes all records while subsequent loads handle only changes (inserts, updates, and deletes).
- Maintains data accuracy and consistency over time.
- Adjusting all tables to be sent via API request to Dataverse:
- Aligns the data with the target system’s requirements.
- Ensures seamless integration and functionality post-migration.
- Sending records to Dataverse using its Web API using asynchronous, multi-threaded requests—more details in the Technical Stack section.
- Validation and testing
Before the final migration, we carried out multiple trials by uploading data into Dataverse and rigorously testing the migrated solution. For several days the owners of the application performed various kinds of tests including:
- Data tests – executing queries against databases on both systems to verify that no changes occurred
- Functional tests – testing the correctness of all plugins and additional logic enriching data on Dataverse
- End-to-end tests – replicating supported scenarios of usage of the application to make sure that the application works as intended
Checkpointing
Checkpointing was a key factor in the data migration process to ensure data integrity and to enable easy recovery in case of failures. Key Points of Checkpointing:
- Monitoring: we could continuously track the progress of the migration and logs information at each checkpoint to monitor for any issues.
- Recording State: saved the current state of the migration process at each checkpoint. This includes the last successfully transferred data and the status of ongoing operations.
- Recovery: In case of failure, use the last checkpoint to resume the migration from where it left off, without a need to starting from scratch.
Alternate Keys
Each Microsoft Dataverse table row has a unique identifier formatted as a GUID. These identifiers are the primary key for each table. They are automatically assigned by Dataverse on row creation which means that they could not be used during the pre-processing stage in the relational database. As an alternative, it is possible to set an alternate key for a table – a column or a set of columns that can uniquely identify a record. Thanks to alternate keys there was no need to know the GUIDs assigned by Dataverse to identify and update rows or join tables.
Alternate keys have the following properties which had to be considered during the migration:
- Each table for which we want to perform an Upsert operation, needs to have an alternate key. It can be formulated based on more than one column. Concatenation of this operation need to be unique across whole table
- Columns that have the Enable column security property enabled can’t be used as an alternate key.
- Make sure to eliminate nulls. While it’s not mandatory to have not null or not empty enabled for alternate keys, we recommend not to use columns with empty values
- Alternate Key has some limitations, such a column cannot contain characters like:
“/,<,>,*,%,&,:,\\,?,+” - Allowed value types:
Decimal, Whole Number (Integer), Single line of Text (String), Date and Time, Lookup, Choice - You can find more information in Microsoft’s guide on defining alternate keys.
Web API
The Dataverse Web API provides a RESTful web service interface that allowed us to interact with data in Microsoft Dataverse using Python as our main language. The Web API implements the OData (Open Data Protocol) version 4.0, which is the standard for building and consuming RESTful APIs over rich data sources.
Before committing to this approach, we did some benchmarks with Web API and below you can find a table with a comparison of 2 different approaches creation of records in Dataverse. The results gave us confidence to fully focus on solution based on Web API, and include this approach in our process.
| Process | Number of records | Description | Number of columns | Duration |
|---|---|---|---|---|
| Data Flow | 100k | Inserts | 38 | ~ 1h 20 min |
| WEB API – Batch InsertUpdate | 100k | Inserts | 38 | ~ 7 min |
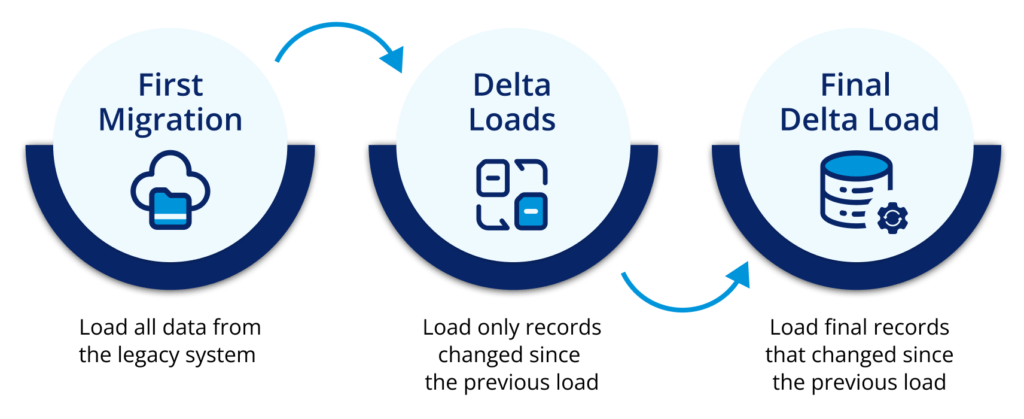
The Delta Approach
Keeping the system accessible for users is crucial, we couldn’t afford to disrupt daily operations for days or weeks while moving data. This is where migration focused on delta comes in place.
What is a delta migration? It’s a type of migration that only transfers data that is different between the source and the destination. Delta simply means change or difference. Instead of moving everything again, it is only focused on moving what’s new or changed since the last migration.
A delta migration-centered solution breaks the migration process into two phases: the initial migration and the delta migrations. In the initial phase, you move the entire dataset to the new location. Afterward, as new records are created or changed in the source system, the delta migration phase takes over. It ensures that only these changes are transferred. Additionally you can execute as many iterations of delta migration as you need.
Delta migrations are great for moving data when the source system is still in use. Without them, you would have to move all the data again every time there is a change, which is inefficient and time-consuming. Thanks to the delta migration feature, you can complete your project with minimal or no downtime for users. This means your business operations can continue without interruptions, making the migration process smooth and efficient.
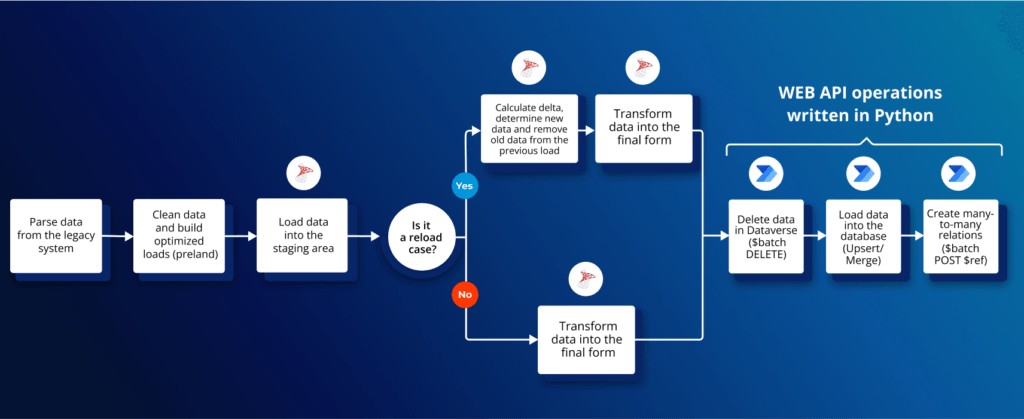
Technical Stack
- Python: we decided to interact with Dataverse programmatically, using its Web API. It meant that we also had to choose a programming language which would be used to develop code for gathering data, organizing it into payloads in HTTP requests, sending the requests and processing responses. We chose Python because of its out-of-the-box integrations provided by the large community, the quickness of prototyping and because our team of data engineers had the most experience in it. The key library used in order to utilize Dataverse API’s parallelism was grequests – asynchronous, multi-threaded version of requests. With this in place, we developed three main types of actions:
- Upserts: all new or modified rows were sent to Dataverse using the Microsoft.Dynamics.CRM.UpsertMultiple type of a request. We found that including 100 rows of data per request and sending the maximum allowed number of requests in parallel yielded the fastest results.Deletes: if the delta logic on SQL Server detected a row that had disappeared between loads, then such row also had to be deleted on Dataverse. At the time of the migration, the Microsoft.Dynamics.CRM.DeleteMultiple action was in preview and couldn’t be used on standard Dataverse tables, so we were sending DELETE requests grouped in batches instead.
- Many-to-many relations: Some tables had defined many-to-many relations that needed to be created separately. They were being created with batch multi-requests containing 100 POST requests each, declaring relationships using the $ref endpoint.
- Docker: the migration solution had to be independent from a machine where it would be ultimately executed and we had to ensure uniformity and stability for all developers working on it. To fulfill these requirements, all scripts and tools were containerized into Docker containers managed with Docker Compose commands. Combined with code versioning on a Github repository, it provided a simple and quick way to deploy the tool anywhere and to redeploy it after implementing changes.
- Microsoft Azure Virtual Machine: The containerized code was deployed on a small virtual machine with Ubuntu operating system. It didn’t require a lot of memory nor computing power, because the majority of actions were executed elsewhere.
- Azure SQL and SQL Server: Before we could send the data to Dataverse API, a number of transformations and tests had to be performed on it. We decided to develop them on a relational database using SQL queries. To stay in the Azure ecosystem, an Azure SQL instance of SQL Server was used.
- Bulk copy program utility (bcp): The first stage of data preprocessing was loading all data from source csv files into SQL Server. We had tested a lot of methods before we settled on using Microsoft’s bulk copy program utility (bcp). This tool was created specifically for optimized imports and exports to and from SQL Server. In the case of this migration, bcp turned out to be several dozen times faster than any other approach.
- Data build tool (dbt): After the data had been loaded into a relational database, it had to be cleaned and transformed—the most important transformation being the calculation of delta between the newest data load and the preceding one. These operations shared many common elements which repeated for every processed table. Pasting the same, repeatable code to all SQL scripts and applying any modifications would be cumbersome. Additionally, the migration tool was being developed on multiple environments—new changes had to be tested on a development database before being applied to the production database. As a consequence, the same SQL scripts had to be executed multiple times on different databases. We used dbt as the solution to these challenges. All common elements of the transformations were extracted to a set of reusable macros. Environments could be managed with dbt profiles configured with environment variables.
- Dagster: All of the tools described above and the dependencies between them shaped a flow to be automated, organized and parallelized. Such a flow could be translated into a directed acyclic graph (DAG), so the natural solution was to use an orchestrating platform to manage the flow for us. We considered such tools as Airflow and Mage, but in the end we chose Dagster. It convinced us mostly with its great integration with dbt and a clear, readable UI. Thanks to Dagster, the task of automating the process became just a matter of defining assets from our Python functions and dbt models and declaring dependencies between them. Dagster handled executing all elements of the flow in the right order and in parallel for us. Such a job could be triggered from the UI. We could also monitor statuses and read logs of all current and past job runs. Dagster also offered us a parametrized system of automatic task retries after encountering failures. Last but not least, Dagster’s UI allowed us to present details of the flow and results of the migration to the client, regardless of their level of technical skills and of how familiar with the tools they were.
The final flow including the technologies used in it looked in the following way:
Results
Without the delta approach and using a Dataflow, the migration was estimated to last over 30 hours. It also involved a lot of additional manual work such as detecting missing rows caused by plugin failures and reloading them.
After implementing the process described in this article, the final migration took 30 minutes. The application was disabled for 60 times shorter time than the initial expectation.
Conclusions From the Project and Actionable Advice
Based on our experience from this project, we prepared a list of tips that could be useful for fellow engineers working on similar large migration projects.
- Start testing your flow on a full snapshot of the dataset as early as possible. A script that works on a sample of the data might fail when faced with edge cases.
- Implement checkpointing to ensure data integrity and to enable easy recovery in case of failures during data loading.
- Move as much data transformation as possible into a staging phase. It will be much faster to process data in a relational database before loading it into Dataverse. This is particularly important when the dataset is big.
- Turn off plugins and flows which aren’t required during the migration.
- Automate the process as much as possible—parallelization of request processing, along with a retry mechanism, makes the solution efficient and stable.
- Use the delta approach to reduce downtime of the migrated application.
- Use alternate keys on all migrated tables.
- Thoroughly cleanse data before sending it to Dataverse to avoid API errors.
Authors
Mateusz Wiatrowski
Senior Data Engineer
Mikołaj Szymczak
Data Engineer
Would you like more information about this topic?
Complete the form below.