
Unstructured data is an incredible source of insights for businesses. It can reveal patterns in customer behavior, help improve operations and guide strategic decisions. But much of this data goes unused because it’s messy, unstructured, and hard to analyze with traditional (read: statistical or NLTK tools) tools.
It is estimated that 80 to even 85% of all business information exists in an unstructured format. This includes emails, memos, notes, standard operating procedures, documentation, knowledge articles, and industry-specific records—such as clinical notes and study protocols in pharmaceutical R&D or batch reports in manufacturing. However, these datasets are often inconsistent and difficult to process at a scale.
This is where AI language models come in. They are the way we handle unstructured data. They can understand complex text semantics, find hidden patterns, and extract information into a structured form that can be processed by computers.. But this analysis is not limited to text. With a pipeline of different models, it is possible to turn voice recordings into actionable insights or extract features from images.
While large language models (LLMs) aren’t always the only solution—smaller, more focused models can work well for certain tasks—they offer a level of flexibility and capability that’s hard to match. This is especially important for cases where privacy and security requirements are strict, or when we have huge amounts of data to process. Small language models (SLMs), fine-tuned for specific domains, can be comparable in performance and accuracy with lower latency and cost compared to LLMs. It’s no surprise that SLMs can be found on our list of the most impactful AI Trends for 2025.
The Power of Unstructured Data
Unstructured data offers a wealth of knowledge for businesses across industries:
- In manufacturing, for instance, safety reports, batch reports, etc., can hide key information that can be used for process improvements.
- In retail, customer reviews and feedback provide invaluable insights into product performance and consumer preferences.
- In the pharmaceutical industry, the value of unstructured data is even more pronounced. Patient health records, safety reports, and clinical notes contain rich, detailed information about disease progression, treatment outcomes, and patient experiences. These insights can drive innovation in drug development and improve patient care.
However, the fact that much of this data is unstructured makes it harder to analyze and use effectively.
Unstructured data doesn’t fit neatly into rows and columns. It comes in formats like free-text notes, audio files, or images, which are not immediately suitable for traditional analytical methods. As a result, businesses often miss out on the insights hidden in their own data.
Why Analyzing Unstructured Data is a Challenge
Unstructured data presents unique obstacles that make it far more difficult to analyze than structured data. Unlike formatted tables or databases, unstructured data comes in forms like free-text notes, PDFs, or even audio recordings, images and audio. These formats lack a consistent information structure, making it hard to extract relevant information at scale.
In the pharmaceutical industry, clinical narratives are a prime example of unstructured data. These records, often written by healthcare professionals, are filled with medical jargon, abbreviations, and inconsistent formatting. The way a physician describes a symptom, or a treatment outcome can vary widely between individuals, and even between entries from the same person.
In commerce, product feedback or customer complaints can come in the form of text documents. Customers can freely describe their thoughts, providing different information. Building a solution that can automatically extract information from those narratives and act based on those records, would help to drastically rebuild the customer care processes, making them more cost-effective and providing faster responses to customers.
And one more thing, unstructured data analysis not only means extracting information from text and getting insights from it. Since business operations mainly consists of processing unstructured data, this step – unstructured data extraction – is often the first element of more complex workflows for automating business processes. This optimization of business processes leads to more efficient operation of a company.
Traditional analysis methods often fall short in capturing the nuances of such data. Rule-based systems struggle with contextual dependencies, while manual review is time-intensive and prone to error. As a result, key insights can remain buried within the data.
This is where advanced AI tools, like language models, begin to shine.
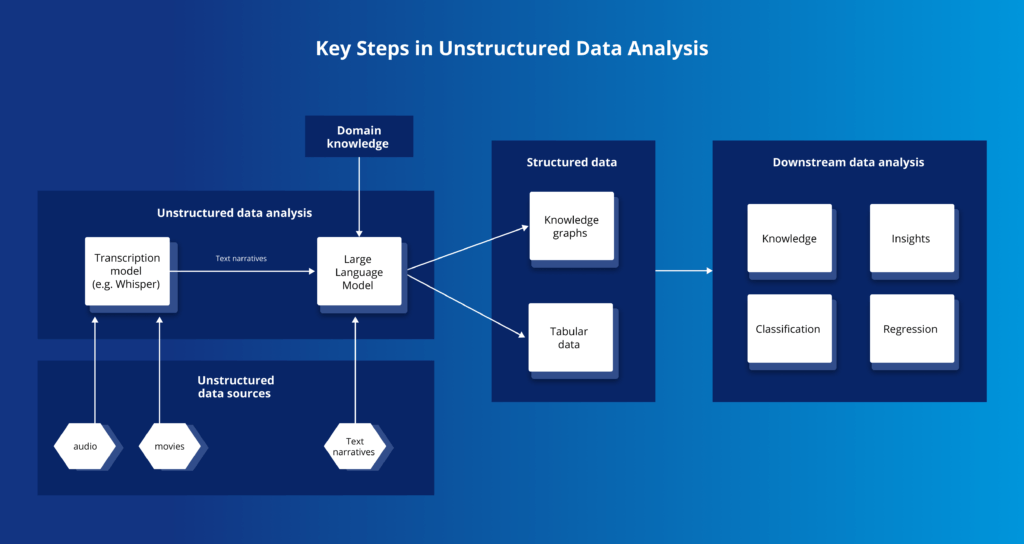
How Language Models Unlock the Potential of Unstructured Data
Language models are designed to understand, process, and extract meaning from natural language—something traditional systems often struggle to achieve.
The roots of language models lie in natural language processing (NLP), a field of AI that focuses on enabling machines to understand human language. Early models relied on rule-based systems and basic statistical methods, but the real breakthrough came with the introduction of transformer neural networks. Over the past decade, advancements in deep learning have given rise to multiple language models: first BERT, then GPT-3, and the models we have today (including reasoning models like OpenAI o1).
LLMs excel at recognizing context and identifying patterns in unstructured datasets. For example, they can interpret the nuanced language found in clinical narratives, connecting terms like “hypertension” and “high blood pressure” as equivalents or recognizing relationships between symptoms, treatments, and outcomes. This contextual understanding makes them invaluable for unlocking the insights hidden within unstructured data.
Importantly, language models are not one-size-fits-all solutions.
While LLMs are incredibly versatile and powerful, smaller, fine-tuned models for specific domains can also perform well for specific tasks. For instance, a lightweight, domain-specific model might be sufficient for extracting key phrases from patient records or summarizing safety reports. The choice between large and small models often depends on the complexity of the problem and the resources available. Data safety, privacy, and regulatory compliance may also impact the decision process here.
Breaking Down Unstructured Data Analysis
The process of analyzing unstructured data involves several steps:
- Data collection and digitization
Gathering unstructured data from sources such as text narratives, audio recordings, and images. - Preprocessing
Cleaning and preparing the data to ensure consistency and quality. - Designing domain-model
Designing a meta-model for representing what information is going to be extracted and to what form. - Applying models
Using LLMs to extract insights, classify data, or generate structured outputs like knowledge graphs. - Analysis and interpretation
Translating the extracted information into actionable insights for business decision-making.
When this process is executed correctly, the results can be remarkable. In the healthcare sector, a great example is the analysis of Electronic Health Records (EHRs), which often serve as a rich but underutilized source of real-world data. Traditionally, processing these records manually or with older NLP algorithms and models has been slow, and prone to human error, and lacking the expected accuracy.
With LLMs, the game changes. Processing a single health record now takes just seconds and costs significantly less, making it thousands of times faster and more cost-effective than manual methods. Not only do these models handle unstructured text with greater accuracy, but they also enable downstream applications such as building knowledge graphs, identifying trends, and automating reporting processes.
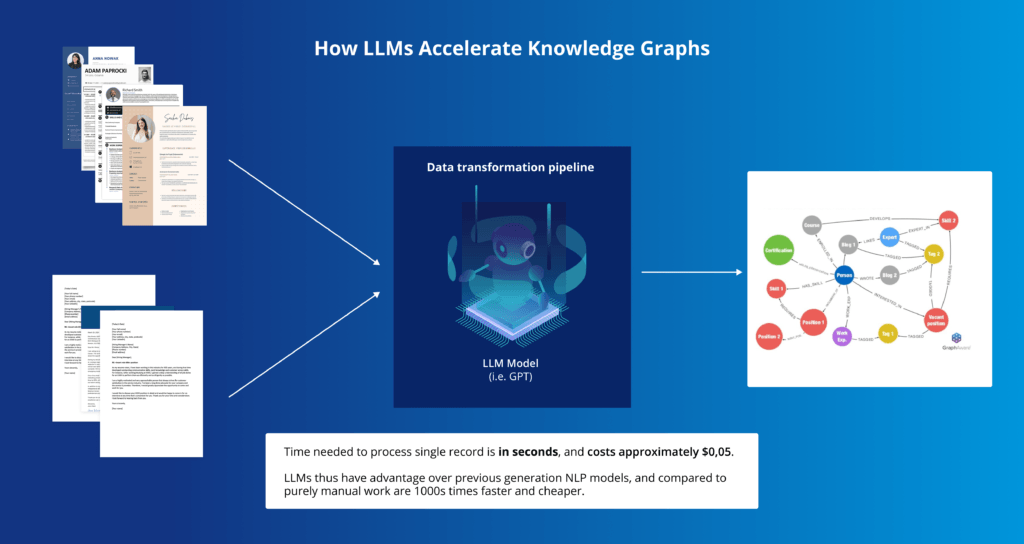
Case Study: Transforming Safety Data Analysis with Language Models
One of the most fascinating implementations of our practice comes from the pharmaceutical sector. However, in this case, the industry itself is less relevant — it’s about managing safety at manufacturing facilities.
Our client, a global leader with decades of experience in the market, faced a common but complex challenge. For more than two decades, the company recorded safety incidents at its manufacturing facilities. These records included structured data, such as categories and locations, as well as unstructured text narratives describing risks and actions taken. While this dataset represented a rich source of information, the unstructured elements made traditional analysis methods ineffective.
The goal was clear: to analyze the collected data and identify patterns and do a group root cause analysis that could lead to improvements in safety procedures.
Because of the scale and privacy requirements of the data, we needed to use an offline model for initial analysis. We did a comparison of accuracy and performance across several models, including Gemma2 27B, Phi-3 14B, and Mixtral 8x7B. In the end, we did the initial analysis with the Gemma2 27B model (we will publish a more in-depth analysis of the results in a separate article).
The model was served within the organization’s cloud infrastructure, ensuring that all data remained secure and compliant with privacy regulations. This approach allowed for a high level of confidentiality while leveraging the full power of advanced AI technology.
The process included several steps. The first step involved the development of a data meta-model, designed to structure the information extracted from the text narratives found in the incident reports. By analyzing descriptions and identifying key patterns in the extracted information, we were able to draw meaningful insights from previously underutilized data. This created an entirely new, structured dataset that allowed the organization to analyze trends and correlations that had been impossible to uncover using traditional tools.
The process combined the strengths of the language model with statistical and machine learning techniques, enabling the extraction of actionable insights while preserving the context and nuance of the original narratives.
Results?
The meta-model provided a foundation for processing and interpreting data at scale, while a custom dashboard presented insights in an accessible format for decision-makers.
Key findings included recurring patterns in safety incidents linked to specific equipment types and procedural gaps. These insights directly informed updates to the organization’s safety processes, significantly reducing the likelihood of future incidents.

AI Agents Implementation: Autonomy, Architecture, and Ethics
Uncover the power of Agentic AI and small language models. Hear how organizations are moving beyond pilots to scale AI successfully.

Building Business Cases for AI
Learn how to turn AI’s immense potential into actual business value. Our experts cover identifying the right use cases and talk about the foundations needed to succeed.

Agentic AI—Unlocking the Power of Agentic AI: Industry Insights and Challenges
Uncover the power of Agentic AI and small language models. Hear how organizations are moving beyond pilots to scale AI successfully.
Unlocking the Future of Unstructured Data
Large Language Models are opening doors to insights in places that used to be nearly impossible to access. They allow businesses to find value in unstructured data—whether it’s patient records, safety reports, or customer feedback—and turn it into meaningful actions.
Using LLM to analyze text opens doors for advanced automations of handling information in business processes. Those automations can significantly reduce time needed to process a single record giving a company competitive advantage.
We’ve seen this happen in practice. Companies are using GenAI to solve real-world problems. And the results are clear: faster analyses, lower costs, and smarter strategies.
But it’s not all smooth sailing. Bias in data can still creep into analyses, and it’s something businesses need to be mindful of. Plus, not all language models are created equal. Choosing the right model for the job is critical because each has its own strengths and weaknesses.
Even with these challenges, the potential of language models is huge. As this technology keeps advancing, we’ll see more opportunities to tap into the value of unstructured data analytics — and that’s worth getting excited about.
Curious how this fits into a structured AI strategy? Download our white paper: The BIG AI Framework.
Would you like more information about this topic?
Complete the form below.