
Are AI-enabled developer tools making testing great again? I evaluated the usefulness of AI-enabled developer tools for software development and am surprised to what extent they can increase a developer’s productivity. On the other hand, unfortunately, I encountered errors that appeared in the generated code. The speed at which the code is generated makes it easy to overlook them, especially the less obvious ones. In this article, I will explain how to use AI-enabled developer tools to boost productivity, while also avoiding potential issues that may arise and create new problems.
Since AI-enabled developer tools like GitHub Copilot became popular1 in programmers’ daily work, the question arose whether they will still be actually needed. These tools can generate not only single statements, but entire methods, and often classes. In addition, the developer, by modifying the generated code on the fly, can adapt the class or method to the project needs.
There is no denying that we are dealing with tools that may soon increase the productivity of development teams (my initial experiments and interviews with colleagues suggest a productivity increase of 50 to even 100%).
Of course, using these tools doesn’t mean we can forget about our role as developers. We still have to be responsible for the quality of our code, and must verify its proper operation and effects. –
So, the question arises: how to develop robust and secure software using AI-enabled development tools? Below is a list of techniques that need to be adopted in order to quickly create software that is both of high quality and secure.
1. Use a practical approach to TDD
Test Driven Development is a method of software development based on an approach in which tests for the created production code are created before the code is developed. One advantage of this approach is the fact that the developer, right after introducing changes in the code, is able to check whether what they wrote passes the previously defined tests. Many bugs can be detected at this level very quickly, practically without the developer leaving their preferred IDE.
Used in its pure form, Test Driven Development can be difficult and tedious to use. Here, however, I will show a practical approach to this methodology 😊.
When product team starts working on a User Story, a meeting called the three amigos meeting is organized. There, the developer, the business analyst and the tester discuss the story that will be implemented. The outcomes here are:
- A common vision of the business purpose and technical implementation of the Story
- A definition of how the developed application functions will be verified.
Let’s take a look at a very simple example:
As a user of my health tracking app,
I want to track my BMI by entering a weight for my defined height once a week,
To keep my weight in a healthy range.
In the case above, the Product Owner, Developer and Tester meet before starting work on this Story. They confirm mutual understanding of the Story’s description. The developer says that BMI calculation will be implemented as an algorithm in the back-end part and exposed by the REST API end-point. Together with the tester, they conclude that the BMI calculation method will take weight (in kilograms) and height (in meters). Therefore, the tester proposes to prepare the following table with test data that will be used to verify the correctness of the algorithm:
| Height | Weight | Expected result |
| 1.6 | 100 | 39.063 |
| 1.83 | 85 | 25.38 |
| 1.61 | 52.5 | 20.25 |
| 1.6 | 31 | 12.11 |
| 0 | 0 | n/a |
| 1.75 | 0 | n/a |
| 0 | 100 | n/a |
| -1 | 100 | n/a |
| 1.6 | -1 | n/a |
| 65 | 1.8 | n/a |
| 183 | 85 | n/a |
| 1.61 | 525 | n/a |
| 1.6 | 251 | n/a |
| 2.51 | 85 | n/a |
| 0.99 | 85 | n/a |
| 1.6 | 29 | n/a |
A sample implementation of the following tests using Java and TestNG is shown below:
public class BmiTest{
@DataProvider(name = "bmi")
public Object[][] bmiDataProvider() {
return new Object[][]{
{100d, 1.6, 39.063},
{85d, 1.83, 25.38},
{52.5, 1.61, 20.25},
{31d, 1.6, 12.11}
};
}
@Test (dataProvider = "bmi")
public void testCalculateCorrectBmi(double weight, double height, double expectedBmi) {
var calculatedBmi = Calculator.calculateBmi(weight, height);
Assert.assertEquals(calculatedBmi, expectedBmi, 0.01);
}
@DataProvider(name = "incorrect_bmi")
public Object[][] bmiIncorrectDataProvider() {
return new Object[][] {
{0.0, 0.0}, //parameters cannot be 0
{0.0, 1.75}, //weight cannot be 0
{100.0, 0.0}, //height cannot be 0
{100.0, -1.0}, //height cannot be negative
{-1.0, 1.6}, //weight cannot be negative
{1.8, 65.0}, //messed up the order of the parameters
{85.0, 183.0}, //wrong unit of first parameter
{525.0, 1.61}, //wrong unit of second parameter
{251.0, 1.6}, //weight cannot be greater than 250 kg
{85.0, 2.51}, //height cannot be greater than 2.5 m
{85.0, 0.99}, //height cannot be smaller than 1 m
{29.0, 1.6} //weight cannot be smaller than 30 kg
};
}
@Test (dataProvider = "incorrect_bmi")
public void testCalculateIncorrectBmi(double weight, double height) {
Assert.assertThrows(IllegalArgumentException.class, () -> Calculator.calculateBmi(weight, height));
}
}In this type of approach, the developer is protected against various types of problems both at the time of software development and in the future. Unit tests will be able to detect problems with the BMI counting algorithm. The tester, despite neither having tested nor implemented unit tests themselves, through their contribution to the development of test data secured the application against potential problems.
And yes, AI-enabled tools can generate unit tests based on production code, but shouldn’t tests challenge the developed code rather than rely on it?
2. Use BDD
In the previous section, I showed a very low-level example. In the real world, business is not interested in the code, but rather in the functionality for the end user. In this situation, it is best to use the BDD – Behavior Driven Development approach.
Using the BDD approach is one way to ensure the quality of the software and its alignment with business requirements. This approach involves describing the functionality using test scenarios that are written in a natural language and based on end-user behavior. These scenarios are then used to write automated tests at various levels (unit, integration, acceptance). Just as with TDD, acceptance criteria are created before starting any development work.
This approach has several advantages:
- it facilitates communication between developers, testers and business stakeholders as they all use the same language and format to describe functionality;
- it increases test coverage and error detection as test scenarios are created based on business requirements and take into account different use cases and execution paths;
- it allows for faster and easier adaptation of tests to changes in code or requirements;
- it facilitates keeping always up-to-date business documentation for the application being built.
Let’s take a look at the following example of two acceptance criteria written in Gherkin syntax:
GIVEN user entered height in meters 1.83 and weight in kilograms 85 into BMI calculation form
WHEN user asks for result
THEN the calculated result should be 25.38.
GIVEN user entered incorrect data into BMI calculation form
OR didn’t provide any of data
WHEN user asks for result
THEN system responds with notification that provided data is incorrect.
The verification of these functionalities can be implemented as end-2-end tests using Selenium, Playwright, and libraries such as Cucumber, JBehave, etc.
public class BmiFormTest {
BmiFormPage bmiFormPage; //injected
BmiResultPage bmiResultPage; //injected
public BmiFormTest(BmiFormPage bmiFormPage, BmiResultPage bmiResultPage) {
this.bmiFormPage = bmiFormPage;
this.bmiResultPage = bmiResultPage;
}
@Given("User entered height in meters 1.83 and weight in kilograms 85 into BMI calculation form")
public void userEntersHeightAndWeight() {
bmiFormPage.enterWeight(85d);
bmiFormPage.enterHeight(1.83);
}
@When("User asks for result")
public void userClicksCalculateButton() {
bmiFormPage.clickCalculateButton();
}
@Then("The calculated result should be 25.38")
public void theCalculatedResultShouldBe() {
var bmi = bmiResultPage.getBmiResult();
Assert.assertEquals(bmi, 25.38, 0.01);
}
}3. Static code analysis
The use of static code analysis is intended to check the source code for errors, security vulnerabilities, and non-compliance with standards or best programming practices, all without having to run the software. This technique has many advantages, such as:
- the ability to detect problems early in the development process, which can save time and costs;
- the possibility to improve code quality by applying best practices;
- the ability to ensure code security by detecting potential vulnerabilities, such as SQL injection and XSS attacks.
Here is a very simple example. We have a repository class that holds a list of customers. In this class we want to implement a method that returns the customer based on its ID number (side note – in Spring we don’t even need to implement such a method, but let’s assume for educational purposes that we are not using Spring in our application 😊).
After typing the following comment in the body of the class
//find customer with Id numberGitHub Copilot suggested the following code:
public Customer getCustomerById(Long id) {
return customers.stream()
.filter(customer -> customer.getId().equals(id))
.findFirst()
.orElse(null); // 1
}At first glance, everything is OK. The method works as expected. We only need to handle the situation when the customer we are looking for is not in the repository and the method returns null.
And here begins an interesting part. When I saw this method for the first time, it looked OK to me. But soon a teammate noticed that findFirst() returns an Optional type, so we can get rid of line 1 and return Optional<Customer> instead of Customer from the original method. Thus, the end user will have to extract the value thus forcing them to handle the case where there is no value. This makes your code more secure now and in the future.
Someone might say that such obvious problems will certainly quickly be picked up by the developers themselves. However, with the high speed of code generation, it’s easy to miss these and many other less obvious code problems. And even if the function itself works well, it may turn out that we create some kind of technical debt.
To detect these types of problems, it is worth using static code analysis tools like SonarQube or others that will allow us to fix such problems quickly.
4. Continuous Delivery
To combine the techniques discussed above into one coherent SDLC (Software Development Life Cycle), it is best to use the Continuous Delivery approach. The Continuous Delivery approach has been known in software engineering for at least a decade. This approach is based on several pillars:
- automation (of everything: builds, tests, deployments),
- building fast loops (thanks to, among others, building automatic implementation pipelines),
- continuous improvement and a culture of cooperation between dev and ops teams.
The development of a new functionality in the application should start with a three amigos meeting. Next, the developer builds that new functionality into the application while creating unit tests that have been designed together with the tester. When the feature is ready, the developer commits the code to the repository. Then, thanks to the automatic deployment pipeline, verifications of the correct operation of the application at various levels are carried out one by one:
- static code analysis – its semantic correctness and alignment with the predefined best practices are checked. If this gate passes, then executed are…
- unit tests – i.e., all tests (small and large) that verify the operation of the application in memory. If this gate passes, then executed are…
acceptance tests – after building the package and deploying it to the testing environment, end-2-end tests are executed, which are also business acceptance tests.
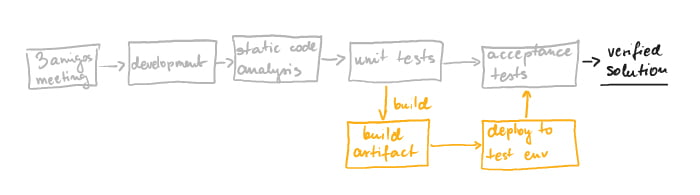
Using the Continuous Delivery approach in software delivery has many advantages:
- it makes introducing changes to the application faster and easier, because you do not have to manually test the code,
- it increases the security and reliability of the software as the code is checked and verified by automated systems.
The renaissance of software testing?
There is no denying that AI-enabled developer tools will significantly influence how we develop software in the near future. Personally, I think they will greatly increase the productivity of individual programmers as well as entire product teams. Interestingly, however, I believe that we will be dealing with a “renaissance” of software testing.
A significant increase in productivity in building new functionalities can in this case shift the focus from writing code (which in many cases can be easily generated) to verifying that the code itself is correct and secure, and that the functionality it implements actually meets business needs. Approaches such as “shift left“, “agile testing“, “test automation“, “continuous delivery” will be crucial to ensuring the quality and security of the created software.
[1] See google trends: https://trends.google.pl/trends/explore?date=2021-06-01%202023-04-20&q=github%20copilot&hl=pl
Would you like more information about this topic?
Complete the form below.