- 1. From the Classic Data Warehouse Model to Big Data Modeling
- 2. Core Principles of Data Modeling for Big Data
- 3. Real-Time Data Analytics and the Models That Enable It
- 4. Data Modeling and Visualization: Where Structure Meets Insight
- 5. Predictive Data Modeling: Turning History Into Foresight
- 6. Healthcare Data Analytics: A High-Stakes Use Case
- 7. Cloud-Native Platforms and the Modern Data Warehouse Model
- 8. Data Modeling Best Practices: Building for Scale and Longevity
- 9. FAQ
Every organization running analytics today is also running a quiet experiment. Can the way their data is structured actually support the decisions they need to make? Most have invested heavily in platforms and analytics talent. Far fewer have given the same attention to the data models that determine whether any of it produces reliable output.
That gap matters more than it seems. Data modeling is the practice of defining how data is organized, related, and made available for analysis. It is not glamorous work, and it rarely gets the strategic attention that platforms and tools do. But it is the layer that everything else depends on.
This article traces how data modeling has evolved from its roots in classical warehouse design to the demands of real-time and predictive analytics, and what it takes to build models that hold up as data volumes and business expectations grow.
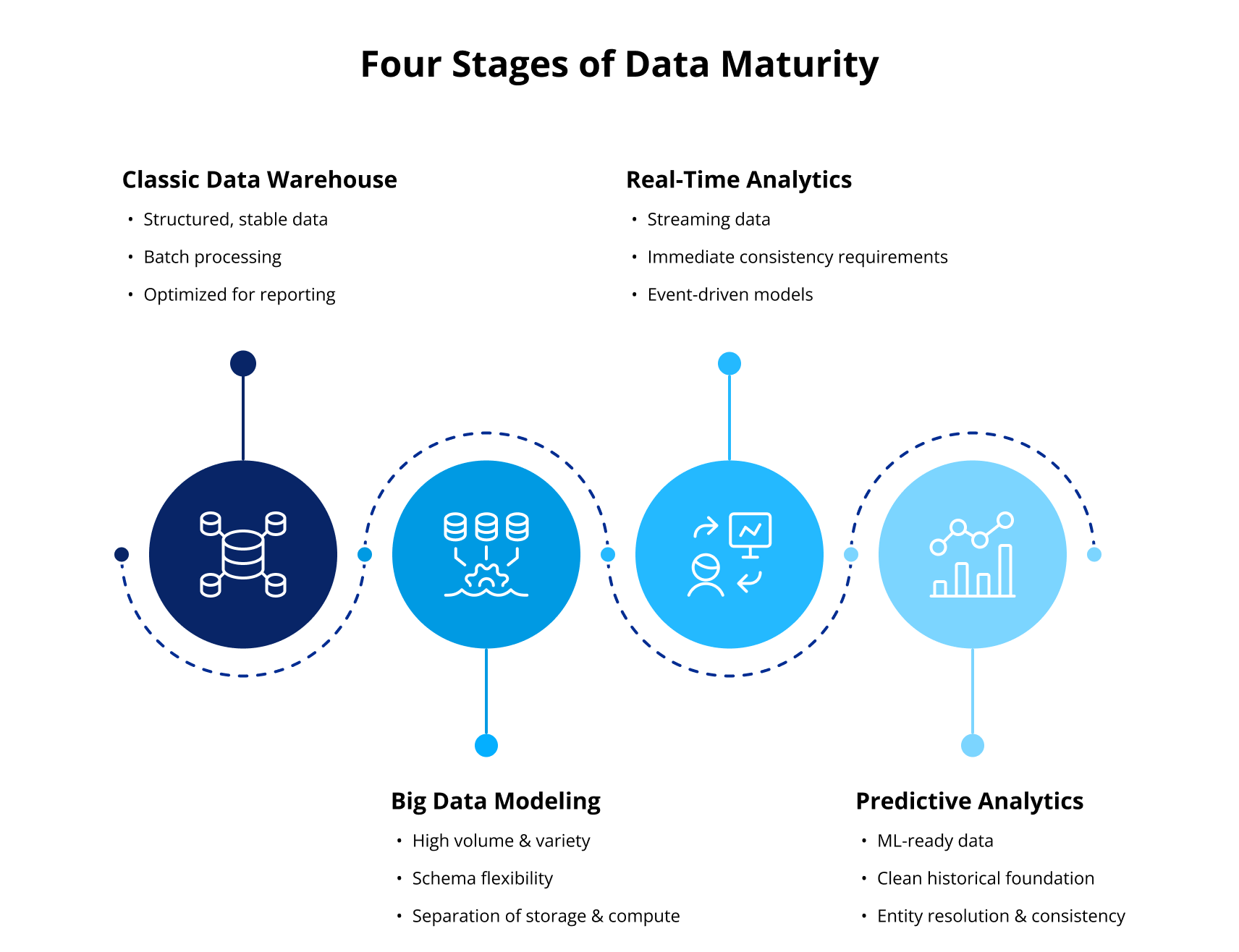
From the Classic Data Warehouse Model to Big Data Modeling
The data warehouse model that dominated enterprise analytics for decades was designed for a predictable world. Data structures were organized to reflect how the business thought about its operations, and that approach worked extremely well within those constraints. For stable, structured reporting it still does.
Since then, data reality has changed considerably. Volume has grown well beyond what classical warehouse architecture was designed to handle, and what once arrived in predictable batches now streams in continuously alongside traditional inputs. The processing architecture that made the old model reliable becomes a constraint when the environment it was built for no longer exists.
Big data modeling extends the warehouse’s underlying logic into this wider environment. The fundamental concerns stay the same but the technical constraints change considerably. Schema flexibility becomes a design requirement, and the separation of storage and compute that cloud platforms have made practical opens up modeling patterns that on-premises architecture simply could not support.
Core Principles of Data Modeling for Big Data
The shift to big data environments raises the stakes for the data modeling discipline. Modularity, documented transformation logic, and governance built into the design from the start are what separates models that scale from models that accumulate technical debt.
Dimensional modeling remains central here, still the clearest way to align data structure with how the business actually asks questions. What has changed is how that logic gets implemented at scale. Data Vault 2.0 handles the auditability and flexibility that modern environments demand, while tools like dbt bring version control and documentation into the modeling workflow itself.
Good Data Modeling is an ongoing discipline, and data modeling for big data environments specifically requires that rigor to be built in from the start rather than imposed later.
Real-Time Data Analytics and the Models That Enable It
Real-time data analytics demand more from the underlying model than speed alone. The ability to act on data as it arrives depends on modeling decisions made well upstream, particularly how events are keyed, how entities are defined across streams, and how late-arriving data is handled.
Moving from batch ETL processing toward streaming architectures changes what the model needs to do. Where batch processing could tolerate schema ambiguity and clean things up on the next run, streaming cannot. Inconsistencies surface immediately and propagate fast. A model built for real-time data analytics needs to treat those constraints as design requirements from the beginning, not problems to solve after the pipeline is live.

Data Modeling and Visualization: Where Structure Meets Insight
The trust people place in a dashboard is borrowed from the model underneath it. When data modeling and visualization are treated as separate concerns, the result is reports that look authoritative but quietly disagree with each other, requiring manual reconciliation that erodes confidence over time.
A well-designed semantic layer is where that connection becomes reliable. When metric definitions are consistent and aggregation logic is documented, visual analytics becomes something people can actually rely on rather than verify manually. Data modeling and visualization work well together when the model is built with consumption in mind from the start, not retrofitted to fit whatever the reporting tool expects.
Predictive Data Modeling: Turning History Into Foresight
Predictive modeling depends on the quality of the data beneath it, which is why predictive data modeling and data architecture are inseparable concerns. A model trained on poorly structured historical data will learn the wrong patterns, and those patterns will become increasingly problematic as they scale with the model’s reach.
Good predictive data modeling makes the warehouse layer useful for forecasting and machine learning. Without a clean historical foundation and consistent entity resolution, a model has little chance of learning the right patterns at scale. Organizations that invest in this foundation see measurably better outcomes. When a predictive modeling initiative stalls, the data feeding it is almost always where the problem sits. According to McKinsey, high-performing data organizations are three times more likely to report that analytics contributes at least 20% to EBIT.
Healthcare Data Analytics: A High-Stakes Use Case
Healthcare data analytics operates under constraints that make modeling discipline especially consequential. Data is fragmented across systems that were never designed to work together, and the decisions it informs carry real clinical and operational risk.
The architectural challenge is significant, because clinical and financial data arrive with different structures and governance requirements. Bringing them into a coherent model that supports both reporting and predictive use cases requires careful design at every layer.
Predictive applications in healthcare depend on exactly the kind of clean historical foundation described in the previous section. A peer-reviewed study in Frontiers in Digital Health found that data lakehouses and similar architectures build on the foundational role of the data warehouse in healthcare rather than replacing it. The warehouse layer remains the structural anchor where historical records and AI workflows converge.
Cloud-Native Platforms and the Modern Data Warehouse Model
The modern cloud data warehouse is a fundamentally different tool than its on-premises predecessor, built around elastic scaling and native support for data types that traditional warehouse architecture was never designed to handle.
What has not changed is the dependence on good modeling. Platforms like Snowflake have expanded what’s possible, but the structural decisions that determine whether data is actually usable still have to be made upstream.
Where cloud data warehouse architecture does shift the modeling conversation is in how structured and semi-structured data can now coexist in the same environment. The modeling challenge becomes organizing that flexibility so it serves analytical and predictive workflows rather than just accommodating raw ingestion.

Data Platforms: The Unsung Hero of AI Transformation
This episode explores how modern data platforms underpin every successful AI strategy. We discuss data modernization, governance, and why “data as a product” is key to unlocking AI’s full…
Data Modeling Best Practices: Building for Scale and Longevity
The organizations that get the most value from their data infrastructure treat modeling as an ongoing discipline. A data warehouse built on well-documented, governed models compounds in value over time. One built on undocumented logic becomes harder to use as it grows.
Data modeling in data warehouse environments works best when business logic is captured at the model level, not scattered across individual reports and dashboards. When that logic lives in one place, changes propagate consistently and teams stop maintaining parallel versions of the same metric.
Governance and documentation are where the discipline most commonly breaks down. Models get built, they work, and documentation gets deferred. The cost shows up later when someone needs to understand what a field means or why two numbers don’t match.
Good Data Modeling also means designing for the questions that haven’t been asked yet. Schemas built only for current reporting requirements tend to require significant rework when predictive or real-time use cases emerge. Building with modularity and clear entity definitions from the start reduces that cost considerably.
The shift from classical warehouse design to real-time and predictive capabilities is fundamentally an extension story. Organizations that have invested in solid modeling foundations are better positioned to extend them into new use cases than those rebuilding from scratch. That foundation is also where the business case lives, with faster insights and decisions made on data that’s actually trustworthy. The structural work done early is what makes the difference between a data platform that scales and one that requires constant intervention.
FAQ
What is the difference between a data warehouse model and a data lake?
A data warehouse model organizes data into defined structures optimized for querying and reporting, with transformation logic applied before storage. A data lake stores raw data in its original form and defers structure until query time. Most modern architectures use elements of both, with the warehouse model providing the governed, analytics-ready layer that the broader data estate depends on.
How does data modeling support predictive modeling and machine learning?
Predictive modeling depends on clean, consistent historical data as its foundation. Good data modeling in data warehouse environments ensures that the records used to train and evaluate models reflect accurate entity relationships and documented transformations. Without that foundation, models learn patterns from noise as easily as from signal.
Why does data modeling matter for real-time data analytics?
Real-time data analytics requires decisions about entity definition, event structure, and late-arriving data to be made upstream and locked into the model before data starts flowing. Unlike batch processing, which can tolerate some ambiguity and correct it later, streaming environments propagate inconsistencies immediately. The model is what determines whether fast data translates into reliable insight.
How is data modeling used in healthcare data analytics?
Healthcare data analytics depends on models that can integrate clinical, operational, and financial data within a single governed framework. Because healthcare data carries regulatory and patient safety implications, the model has to enforce consistency and auditability at the structural level. Predictive applications like outcomes forecasting and capacity planning require clean historical records as their input, which the warehouse layer provides.
Would you like more information about this topic?
Complete the form below.