
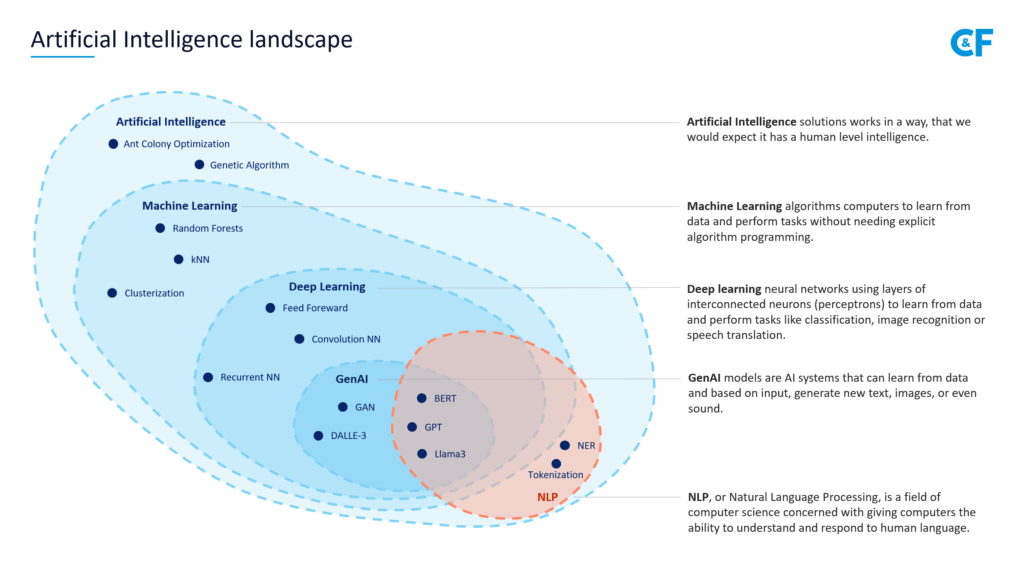
- 1. Let’s Start With the Most Fundamental One—What Is Artificial Intelligence?
- 2. What Is Machine Learning and How It Differs From AI?
- 3. What Can Artificial Intelligence Do for You?
- 4. What Is Generative AI and Why Is It Important?
- 5. What Is a Foundation Model?
- 6. What is a Large Language Model?
- 7. Where Does Natural Language Processing Fit Into the Landscape?
- 8. How Prompts Became the Central Point in Building Generative AI Applications?
- 9. What Is Prompt Engineering?
- 10. All Pricelists of LLMs in the Cloud Talk About Tokens? What Are Tokens?
- 11. Does AI Have More Applications Than Just Chatbots?
- 12. Looking Ahead: The Future of AI in Business
Do you ever feel lost in the sea of confusing AI-adjacent tech terms? You’re not alone. Artificial intelligence (AI) has been a hot topic for years, and with good reason. AI has the potential to revolutionize the way companies operate. But this new technology comes with a whole new vernacular. From machine learning to knowledge bases, and from agent to embedding, it can feel overwhelming for anyone trying to learn the basics. As a manager, navigating this new landscape can be confusing. There’s a lot of jargon thrown around, and it’s important to have some level of understanding of these terms to make informed decisions.
This guide is your key to cracking the code of AI lingo. We’ll break down the essential terms in an easy-to-understand way, so you can confidently navigate the exciting world of AI and unlock its potential for your business.
Whether you’re a manager looking to stay ahead of the curve or simply curious about this powerful technology, this introduction will equip you with the knowledge you need. We’ll explain what these terms mean, why they matter, and how they can be applied in real-world scenarios. So, ditch the confusion and get ready to learn the language of AI!
Let’s Start With the Most Fundamental One—What Is Artificial Intelligence?
Even though this question may seem a bit academical, it’s very important to understand what AI is, and what isn’t. There are number of AI regulations already passed in different parts of the globe (e.g. EU AI Act) that enforce certain polices on AI-enabled systems. Thus knowing what AI is and what it isn’t is very important from the managerial perspective.
Artificial Intelligence (AI) involves developing algorithms, data processing techniques, and models that enable computers to perform tasks usually requiring intelligence such as reasoning, problem-solving, perception, learning, natural language understanding, and decision making.
AI differs from other software systems primarily in its ability to learn from experience (or to be more precise, from data), adapt to new inputs, and make autonomous decisions based on data without explicit programming for each task. While traditional software is designed to perform specific functions according to predefined rules or scripts, AI-driven applications analyze patterns in data (even if they are not evident at the beginning or very complex) and shape its behavior based on those uncovered patterns. As such, it’s commonly said, that AI systems learn from data.
What Is Machine Learning and How It Differs From AI?
Machine Learning (ML) is a subset of Artificial Intelligence focused on developing algorithms that allow computers to learn from data without being explicitly programmed for each task. In essence, Machine Learning enables systems to automatically improve their performance over time by analyzing large datasets and identifying patterns or relationships within them. These insights are then used to make predictions, decisions, or classifications based on new inputs.
ML fits into the AI field as an essential technique that powers many intelligent applications and allows machines to emulate certain aspects of human cognitive functions such as perception, reasoning, learning, decision making, problem-solving, language understanding, etc. In other words, Machine Learning is a core component of most modern Artificial Intelligence systems because it provides the foundation for building models that can effectively process complex data and deliver sophisticated AI capabilities.
What Can Artificial Intelligence Do for You?
These are the three fundamental “services” that AI models can perform (for now, we’ll exclude Natural Language Processing and image processing — they will be covered in the following sections). These services are:
- regression (prediction, forecasting) – this is a type of AI model operation that calculates a certain continuous value for a given set of input data, For example, the model can calculate (estimate) the future value of sales of a certain product or the time until the next needed maintenance check of a machine.
- classification – this is a type of AI model operation that assigns a specific (from the previously given list) category to each set of input data. For example, in the case of emails, it can be labeling “SPAM” and “Not SPAM”. In the case of the analyzed business risks, it may be assigning one of the labels “low”, “medium”, “high”, etc.
- clustering – it is somewhat similar to classification. Only in the former, we know in advance the labels (categories) that we want to give to the data. In the case of clustering, there’s no predetermined list of categories. This type of AI algorithms is primarily used for data analysis. For example to analyze data on loyalty program participants and determine basic customer segments. This can allow you to prepare marketing campaigns and offers tailored to the needs of individual customer segments.
Apart from those fundamental “services” AI models can also analyze images (classification of images, object recognition, object extraction) and process natural language (including classification of text, but also summarization, information extraction, etc.)
What Is Generative AI and Why Is It Important?
Generative AI, a branch of artificial intelligence, is unlike its traditional counterpart. “Classic” (or in other words – predictive) AI excels at analyzing data, making predictions, and recognizing patterns. Generative AI models, however, can create entirely new content. This could be text, images, music, or even virtual worlds (for games or simulations). Currently, the implementation of GenAI comes down to adapting one of many foundation models (e.g. GPT, Gemini, or open source: Llama, Phi, Gemma etc.) and using the results of this model in a specific application.
GenAI models open the door to many exciting possibilities. From personalized marketing campaigns to automatic report creation, generative AI has the potential to revolutionize various fields. Its ability to streamline content creation, enhance productivity, and provide new forms of entertainment makes it a technology worth paying attention to.
What Is a Foundation Model?
A foundation model represents a class of models that have been pre-trained on a massive amount of diverse data across various domains and tasks. These models serve as foundational building blocks for many downstream applications, from natural language processing to computer vision, machine translation, and more. They are designed to be highly versatile and general-purpose (follow instructions provided in a form of a prompt), capable of transferring learned knowledge to new problems with minimal additional training (fine-tuning).
Foundation models often excel at various NLP (Natural Language Processing) or computer vision tasks. With foundation models, the transfer learning process involves minimal adaptation of the pre-trained model for new problems or domains. This contrasts with regular models, where one typically needs substantial retraining on a specialized dataset specific to the target task.
It is essential to note that while “pre-trained models” are a related concept, they differ from foundation models in some aspects. Pre-trained models often focus on specific tasks or domains and can be fine-tuned with task-specific data for better performance within those areas. Meanwhile, foundation models aim to provide a more generalizable starting point applicable across multiple tasks and domains. While pre-trained models typically require further training (fine-tuning) on domain-specific data to achieve optimal results in targeted applications, foundation models are designed for easier transfer learning with minimal additional adjustments.
What is a Large Language Model?
A Large Language Model (LLM) is a type of artificial intelligence model that specializes in processing and generating human language text. It’s called “large” because it has billions of parameters (coefficients) in its neural network. The line between LLMs and Small Language Models constantly moves. But for now, I would argue that Small Language Models are up to 100 billion of parameters[1]. Any model bigger than that should be considered an LLM.
Large Language Models use advanced deep neural networks architectures to understand the patterns and structures within human language. They can analyze the relationships between individual words, phrases, sentences, and larger linguistic context, allowing them to generate coherent and contextually relevant text in response to prompts or questions.
Some popular examples of LLMs include models like GPT (Generative Pre-trained Transformer) developed by OpenAI or Gemini (developed by Google). There are also open source options, including LLaMA (developed by Meta). Since LLMs are foundation models, they have the capacity to perform a wide range of tasks related to text generation, including writing essays, answering questions, summarizing information, and even creating code based on received prompts.
LLMs are continually evolving with improved architectures, training techniques, and scaling methods, leading to more sophisticated language understanding and processing capabilities.
Where Does Natural Language Processing Fit Into the Landscape?
Natural language processing (NLP) is an area within the field of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human languages. Essentially, it bridges the gap between human communication methods and computer understanding by leveraging computational techniques to process large amounts of natural language data.
The ultimate goal of NLP is for machines to be able to comprehend written or spoken text in a way that is both meaningful and useful, much like how humans do with languages such as English, Spanish, Chinese, etc.
NLP plays a significant role in many real-world applications of Large Language Models today, including customer service chatbots, machine translation (e.g., Google Translate), text summarization tools, and even predictive text input on smartphones.
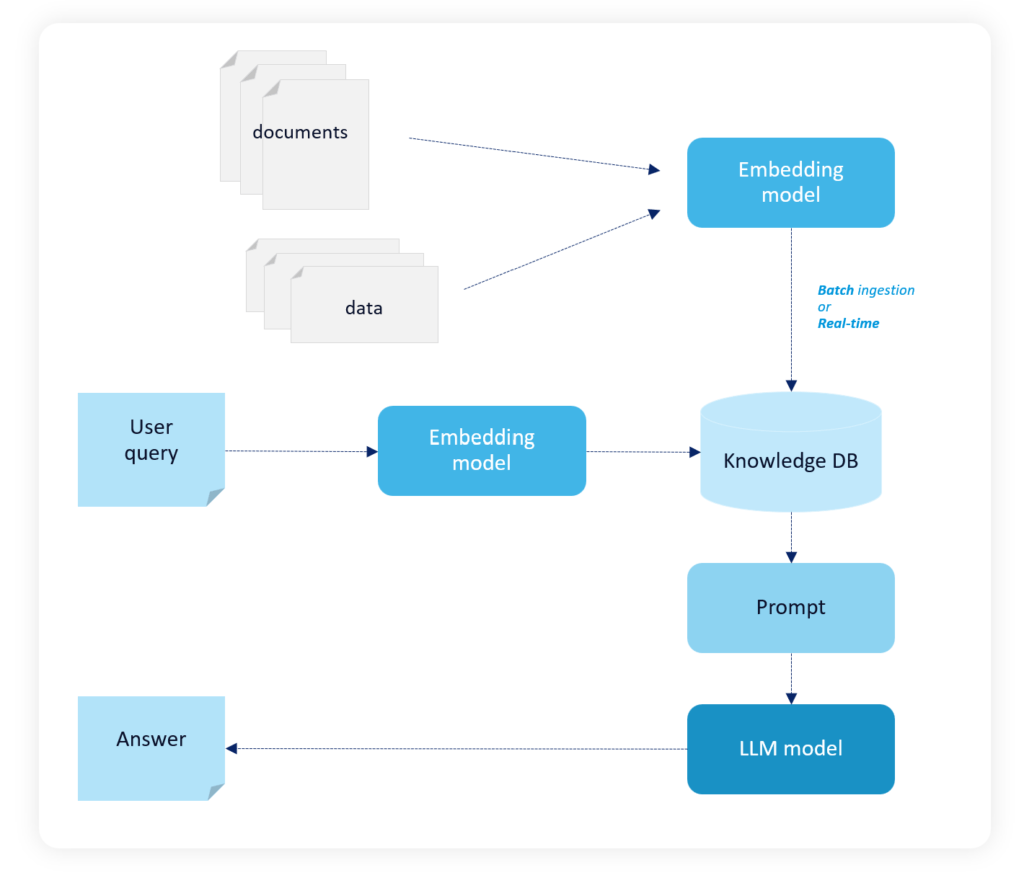
Currently, enterprise solutions utilizing Large Language Models use something called RAG Architecture. What is it?
RAG, or Retrieval-Augmented Generation, is an approach used in building enterprise specific AI-based solutions that combines retrieval process and generative AI models to improve the quality and accuracy of text generation.
It’s an architecture in natural language processing that combines two components: a retriever and a large language model (LLM). This pattern is used to develop a solution working on/with enterprise data without the need for model (LLM) costly fine-tuning.
The retriever searches for relevant information from a knowledge base (vectorized chunks of data), while the LLM uses this retrieved information to generate contextually relevant with use of provided information responses. This approach helps LLMs overcome their limitations of being trained on static datasets and allows them to access and incorporate up-to-date information, leading to more accurate and informative outputs.
In simpler terms, it’s a method for generating content (like writing articles, creating summaries, reports, answers to questions etc.) in two steps:
- Retrieval
Retrieval is a search through information stored in a database or “knowledge base” to find relevant pieces that are similar to the input text provided by users. It’s like searching for specific facts on Google but faster and more tailored to your organization’s context. - Generation
Once it has gathered these related snippets, a generative model then takes over and uses them as “building blocks” or references to create coherence with the original input text. This results in smarter, more accurate, and contextually relevant responses without relying on fixed patterns learned during training alone.
In essence, RAG architecture makes using general LLM models like it would be a model trained on organization specific information, without a need to retrain the whole model. Currently it is the most cost-effective method of implementing large language models in enterprise context.
How Prompts Became the Central Point in Building Generative AI Applications?
A “prompt” refers to a specific instruction or input given by a user or a system that guides an AI model (e.g. Large Language Model) on how to perform a task. The prompt usually contains information, data, or cues necessary for the AI system to generate a desired output based on its knowledge and provided context.
Prompts play a crucial role in determining how an AI system behaves and interacts with users. By crafting clear, concise, and specific prompts, users can influence the accuracy and relevance of the output generated by the AI system.
Very specifically written prompts, containing instructions, examples, or additional context are also used when applying foundation models to specific use cases. For example, with a properly written prompt, the LLM can perform a summary of the data and then write a short introduction to the report generated in the system.
What Is Prompt Engineering?
Prompt engineering is an advanced concept that involves designing and crafting prompts to optimize the performance of AI models, especially in natural language processing tasks. This practice focuses on creating effective inputs or instructions that help guide AI systems toward generating desired outputs while maintaining consistency with their trained knowledge base.
Prompt engineering requires a deep understanding of both machine learning principles and human language usage. Experts in prompt engineering carefully analyze the model’s behavior, identify patterns from its training data, and develop tailored prompts to address specific challenges or improve output quality. These customized prompts are often iteratively tested, refined, and optimized to achieve better results.
All Pricelists of LLMs in the Cloud Talk About Tokens? What Are Tokens?
Computer systems can only deal with numbers and AI models are no exception. Internally, computer represents anything (images, sound and text) as numbers. In order for an AI model to process or generate text, a numerical representation of the input is needed. Before the text is sent to the model, the input text will undergo the process of dividing it into smaller, fundamental elements — tokens. This process is called tokenization. Each token has a numerical representation assigned to it, which can then be processed by the AI model.
Different LLM models can operate on different token sizes. Therefore, 1000 tokens for one model can mean a different amount of text than 1000 tokens for another model. Currently, in the case of one of the most popular models — GPT, 1000 tokens equals more or less 750 words.
Does AI Have More Applications Than Just Chatbots?
Indeed, artificial intelligence (AI) capabilities extend far beyond chatbots. While chatbots represent one of the most visible applications of AI today, they barely scratch the surface of what modern AI systems can accomplish. Here are some key areas where AI is making significant impacts:
- Data analysis and insights: AI can process company’s data, identifying patterns and correlations that humans might miss. This capability is invaluable for making data-driven decisions in areas like market analysis, financial forecasting, and risk assessment.
- Process automation: AI-powered systems can automate complex, multi-step processes across various business functions. This goes beyond basic rule-based automation to include tasks requiring judgment and adaptation.
- Predictive analytics: by analyzing historical data and current trends, AI can make accurate predictions about future outcomes, helping businesses anticipate market changes, customer behaviors, and potential issues.
- Natural Language Processing (NLP): while chatbots use NLP, more advanced AI applications can understand and generate human language in more sophisticated ways, like document summarization, sentiment analysis, and even content creation. These AI capabilities opens new possibilities in company’s unstructured data analysis for deeper insights extraction.
- Computer vision: AI can analyze and interpret visual information from images and videos, with applications ranging from quality control in manufacturing to medical image analysis in healthcare.
- Personalization at scale: using AI, businesses can deliver highly personalized experiences to customers, from product recommendations to tailored content, at a scale impossible with human effort alone.
- Decision support systems: advanced AI can assist in complex decision-making processes by evaluating multiple scenarios and providing data-backed recommendations. This AI capability is used to build next-best-action systems that assists company’s employees in day-by-day business tasks.
When planning the implementation of AI or building AI capabilities, it is always necessary to choose the right solution for a given situation to ensure that it fits your business goals. Consider factors such as the accuracy of the model’s response, information security, and finally the costs of maintaining a system based on AI models.
Below you’ll find a table with common use cases for ML and generative AI. Starting with ones most fit for the classic ML approach, and getting progressively more suitable for the capabilities of GenAI.
| Use case group | Example usage |
|---|---|
| Prediction/forecasting | Risk prediction, Customer Lifetime Value, demand prediction, sales forecasting, maintenance prediction, fraud detection, energy consumption forecasting, health outcome prediction, weather forecasting, etc. |
| Decision intelligence | Decision augmentation, support, automation (in particular, when explainability is required from the AI based system), supply chain optimization, medical diagnosis support, marketing campaign optimization, etc. |
| Segmentation/classification | Object classification, document classification, sentiment analysis, market segmentation, email/issues tagging, customer segmentation, clustering, etc. |
| Recommendation systems | Personalized recommendations engines, advice systems, Next Best Action systems |
| Unstructured data analysis | Named entity extraction from text narratives, knowledge graph building from unstructured data, Text clustering (embeddings based), Key phrase extraction |
| Content generation/text processing | Creative content generation platforms, machine text translation, coding supporting systems, report generation platforms, Content Summarization platforms, SEO content optimization, legal document automation, educational content creation |
| Conversational user interface | Chatbots, automated customer support systems, virtual assistants, digital workers, Interactive Voice Response (IVR) Systems, Education and E-learning Assistants, Healthcare Virtual Assistants, etc. |
Looking Ahead: The Future of AI in Business
For managers, understanding these broader AI capabilities is crucial. While chatbots might be the most visible face of AI for many users, the technology’s potential to transform business processes, enhance decision-making, and drive innovation extends far beyond that. As AI continues to evolve, its applications will likely expand even further, offering new opportunities for businesses to improve efficiency, reduce costs, and create value in novel ways.
We hope, that you are now ready to unlock the full potential of AI in your business! Visit our AI services page to learn more about how C&F can help your organization in this area, including strategy development, implementation, and training. Our experts are ready to help you understand your unique needs and goals and craft a customized AI solution that drives real results.
[1] There is currently no single definition of small language model that would be commonly accepted. We could define the boundary based on number of model parameters. The boundary could be set based on whether it can be run (hosted) on a singe machine or based on some characteristic of a model. In my opinion, the latter is better approach as over time, you would be able to run bigger and bigger models. I would set the boundary between small and large models at 100 B parameters as this is the models size from which chain-of-thoughts reasoning of a model start significantly improve the model performance.
If you’d like to dive deeper into the bigger picture before taking the next step, explore our white paper: The BIG AI Framework.
Would you like more information about this topic?
Complete the form below.