- 1. Data Lake vs Data Warehouse vs Lakehouse: key differences
- 2. Structured vs Unstructured Data: Use Cases for Each Architecture
- 3. Query Performance and Scalability Across Cloud Data Platforms
- 4. Data Governance and Data Quality: Schema-on-Write vs Schema-on-Read
- 5. How to Choose Between Data Lake, Data Warehouse, and Lakehouse
- 6. Data Lakehouse Architecture: Unifying BI and AI Workloads on a Single Platform
- 7. FAQ: Data Lake, Data Warehouse, and Data Lakehouse
The right architecture in organisation depends on data maturity, workload mix, and governance readiness. Data warehouses deliver reliable analytics on structured data. Data lakes handle volume and variety but require discipline to stay useful. The data lakehouse combines open storage with warehouse-grade performance and governance, and currently offers the most practical fit for organizations running BI and AI workloads in parallel. Architecture selection should follow an honest assessment of what your organization can maintain, not what the market is buying.
Choosing between a data lake, warehouse, and lakehouse is rarely straightforward. The options overlap in capability, diverge in trade-off profiles, and often coexist within the same enterprise. The confusion is understandable: each architecture was built to solve a specific problem, and each has since been extended to cover the problems it was not originally designed for.
This article lays out how the three architectures differ structurally, where each one fits, and what to consider before committing to one path or a combination of several.
Data Lake vs Data Warehouse vs Lakehouse: key differences
A data warehouse stores structured, processed data in a predefined schema. Data enters through an ETL (extract, transform, load) pipeline: it is cleaned, transformed, and fitted to the schema before storage. The result is a system that performs well for known query patterns and delivers consistent, audit-ready outputs. This works well for predictable reporting and audit-heavy environments. The downside is flexibility; schema changes can become expensive quickly.
A data lake inverts that logic. Raw data lands in storage first, in whatever format it arrives: JSON files, CSVs, log streams, sensor readings, images. The schema is applied at query time (schema-on-read), which means the lake can hold almost anything without upfront transformation. Without governance, most data lakes eventually turn into storage dumps. Teams stop trusting the data because nobody is fully sure where it came from or how reliable it is.
Data without documented structure, ownership, and lineage tends to accumulate rather than generate value.
A data lakehouse is an architectural pattern that places warehouse-grade capabilities on top of open-format storage. The term was formalized in a 2021 CIDR paper by researchers at Databricks, drawing on implementations that were already emerging: Delta Lake (open-sourced 2019), Apache Hudi (2016, Apache 2019), and Apache Iceberg (2018, Apache 2019). The core idea is that ACID transactions, schema enforcement, and metadata management can be handled at the storage layer, without forcing data into proprietary formats or sacrificing the flexibility that made data lakes attractive in the first place.
The table below summarizes the structural differences:
| Data Warehouse | Data Lake | Data Lakehouse | |
| Primary data type | Structured | All types | All types |
| Schema approach | Schema-on-write | Schema-on-read | Both, with enforcement |
| Storage format | Proprietary | Open (Parquet, ORC) | Open (Delta, Iceberg, Hudi) |
| Typical ingestion | ETL | ELT or direct load | ELT |
| Transaction support | Full ACID | Limited | Full ACID |
| Primary use case | BI, reporting | Exploration, ML | BI and AI workloads |
| Governance maturity required | High | Variable | High |
Structured vs Unstructured Data: Use Cases for Each Architecture
The type of data an organization generates, and the questions it needs to answer with that data, should drive architecture selection more than vendor positioning.
Data warehouses are the right environment when analytical questions are well-defined, the data is predominantly structured, and consistency is required. Finance, sales reporting, regulatory compliance, and executive dashboards all fit this profile. Data Warehouses Solutions are designed for repeatability: the same report run on Monday and Friday should return comparable, explainable results. That guarantee comes from schema-on-write discipline and a well-maintained data model.
Data lakes serve a different class of problem. They are suited to large volumes of raw or semi-structured data where the full analytical value is not yet known at ingestion time. Log files from industrial equipment, clickstream data from web applications, genomic sequences in a pharma research environment: these are workloads where imposing a fixed schema upfront would be either impossible or premature. Data Lakes Solutions support the kind of exploratory analysis and machine learning development that requires access to raw signals, not pre-aggregated summaries. The risk is that without governance investment, the lake fills with data that nobody trusts and few people can find.
Data lakehouses are the practical answer for organizations that need both. A manufacturing company running predictive maintenance needs raw sensor streams for model training and structured production reports for operations leadership. A clinical trial and lab data in pharma needs unstructured research data alongside audit-ready compliance reporting. The lakehouse architecture makes it possible to serve both workloads from a single storage layer, without maintaining two separate systems and duplicating data between them.
Query Performance and Scalability Across Cloud Data Platforms
Performance in data warehousing has historically meant query speed on structured data. Modern cloud data warehouses (Snowflake, Google BigQuery, Amazon Redshift) have achieved significant optimization through columnar storage, compute-storage separation, and automatic query tuning. For BI workloads at scale, they remain difficult to match on raw query latency.
Data lakes, built on distributed storage systems like Amazon S3 or Azure Data Lake Storage, scale horizontally at low incremental cost. The performance challenge sits at the compute layer: without the query optimizations built into warehouses, raw lake queries can be slow and resource-intensive. Frameworks like Apache Spark improve this, but they require tuning and expertise that not every data team has.
Lakehouses address the performance gap through table format technologies. Delta Lake, Apache Iceberg, and Apache Hudi add indexing, caching, Z-ordering, and data skipping on top of open-format files. The result is query performance that approaches warehouse-level speed on analytical workloads, while retaining the storage flexibility and cost profile of a data lake. For organizations building AI/ML pipelines alongside BI, this matters: both workloads can read from the same physical tables, which eliminates data movement between systems and the consistency problems it creates.
Scalability across all three architectures is primarily a cloud infrastructure question today. The meaningful distinctions are in cost structure, operational complexity, and what happens to performance as data volumes grow and query patterns diversify. These are project-specific assessments, and they are worth modeling before committing to a platform.
For organizations operating in industrial environments, the architecture question also intersects with IT/OT integration and real-time data ingestion patterns. Industry 4.0 data architecture introduces constraints that standard enterprise data architecture decisions do not fully anticipate, particularly around latency requirements and edge data processing.
Data Governance and Data Quality: Schema-on-Write vs Schema-on-Read
Governance is where architectural decisions have the most long-term consequence, and where the differences between the three approaches are most significant.
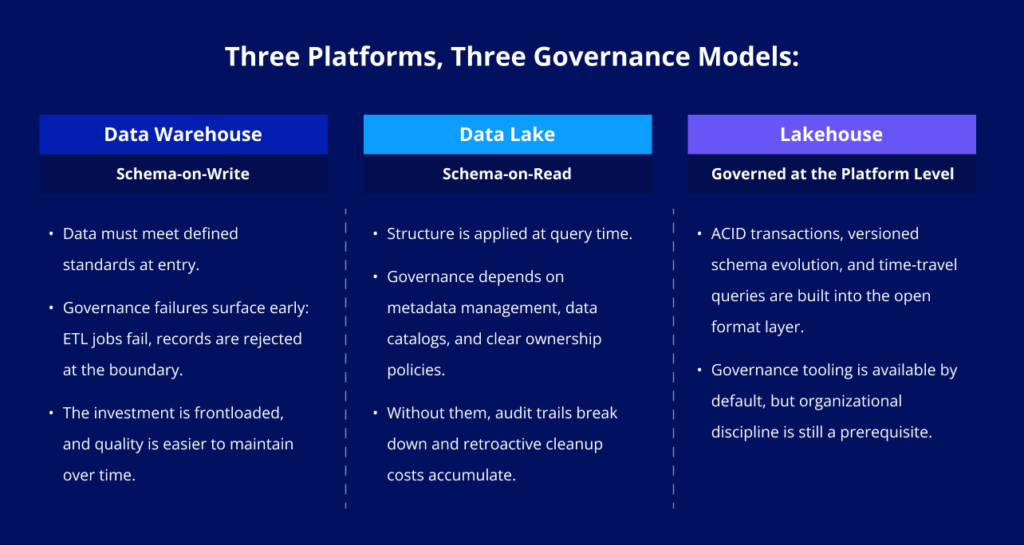
Data warehouses enforce governance through structure. A schema-on-write approach means data must meet defined standards before it enters the system. This makes it easier to maintain data quality, but governance failures happen visibly and early: ETL jobs fail, or data is rejected at the boundary. The governance investment is frontloaded.
Data lakes place governance responsibility on the teams using the data. Without metadata management, data catalogs, and clear ownership policies, a lake becomes difficult to audit and easy to misuse.
The problem is well-documented: organizations that treated a data lake as a zero-governance storage layer found that retroactive cleanup costs often exceeded what proactive governance investment would have required. In practice, many organizations adopt a data lake long before they are ready to govern it properly. This is especially pronounced in regulated industries. For pharma and life sciences organizations, a GxP Compliant Data Lake requires significant upfront architecture work to ensure that data provenance, access controls, and audit trails meet regulatory requirements.
Data lakehouses attempt to provide governance tooling at the platform level. ACID transactions prevent partial writes and read-write conflicts. Schema evolution is versioned and controlled. Time-travel queries allow point-in-time data retrieval, which is particularly useful in audit scenarios. Platforms like Delta Lake and Apache Iceberg handle much of this at the open format layer, independent of the compute engine on top.
Predictive models are only as reliable as the data underneath them. If governance is weak, analytics quality usually suffers as well. A data model built on poorly governed data produces unreliable outputs. Data modeling best practices for predictive analytics depend on consistent, documented, and trusted data as the starting point. Architecture selection shapes whether that starting point is achievable.
The practical implication: governance capacity should be scoped before architecture is chosen. If an organization lacks the data stewardship to maintain a lake, moving to a lakehouse does not automatically resolve the problem. The platforms provide better tooling; they do not substitute for organizational discipline.
How to Choose Between Data Lake, Data Warehouse, and Lakehouse
There is no universal right answer. The architecture that fits depends on data volumes, workload types, team capacity, regulatory requirements, and where the organization is in its data maturity journey.
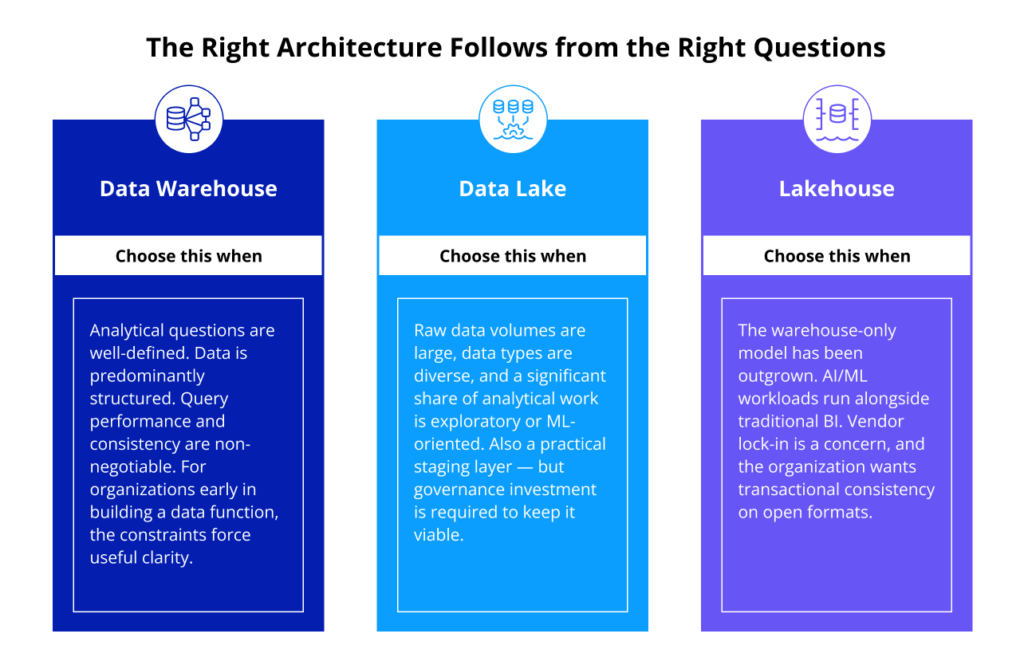
A data warehouse is the right choice when analytical questions are well-defined, the data is predominantly structured, and query performance and consistency are non-negotiable. Organizations in early stages of building a data function often do better starting with a warehouse: the constraints force clarity about what data matters and what it means. For many mid-sized companies, a well-designed warehouse is still easier to manage than a full lakehouse stack.
A data lake fits when raw data volumes are large, data types are diverse, and a significant portion of the analytical work is exploratory or machine learning-oriented. It also makes sense as a staging environment: landing raw data in a lake before selective transformation into a warehouse is a common and practical pattern. That pattern requires ongoing governance investment to remain viable, which is a commitment many organizations underestimate at the outset.
A data lakehouse is the right architecture for organizations that have outgrown the warehouse-only model and are running (or planning to run) AI/ML workloads alongside traditional BI. It is also appropriate when proprietary warehouse formats create vendor lock-in concerns, and when the organization wants to standardize on open formats without giving up transactional consistency.
The decision should follow from an honest assessment of data readiness, team capability, and the specific analytical outcomes the organization is trying to produce. Architecture selection driven by trend-following rather than operational fit creates technical debt that takes years to unwind.
Data Lakehouse Architecture: Unifying BI and AI Workloads on a Single Platform
The most significant practical advantage of the lakehouse architecture is that it collapses two historically separate workflows into one.
In a conventional enterprise data stack, a data warehouse serves the BI function, and a separate environment (typically a combination of data lake storage and Spark-based compute) serves data science and machine learning. These systems share some data, but maintaining consistency between them requires pipelines that move data from the warehouse to the ML environment, or reverse-ETL processes that write model outputs back. Every data movement introduces latency and the possibility of inconsistency.
In a lakehouse architecture, both workflows read from the same storage layer. A Databricks SQL warehouse and a Databricks ML notebook can query the same Delta Lake tables. A Power BI report and a Python feature engineering script operate on the same physical data. When the underlying data is updated, both workloads see the same version, governed by the same ACID transaction protocol.
This matters most in use cases where BI and AI outputs need to be consistent with each other. A sales forecasting model and a sales performance dashboard that disagree create operational confusion and erode trust in both. A demand planning model and a supply chain reporting suite that draw from different data snapshots produce different numbers, and operations teams are left reconciling them manually. The lakehouse architecture does not eliminate all consistency challenges, but it removes the largest structural source of them.
For organizations evaluating platforms: Databricks built the lakehouse concept and remains the primary reference implementation through Delta Lake. Snowflake has extended its architecture to handle semi-structured data and selected ML workloads, which narrows the gap between warehouse and lakehouse. Apache Iceberg has emerged as an open standard that multiple compute engines can read, which makes it attractive for organizations that want to avoid tying storage to a single vendor’s format.
The right platform choice depends on the existing technology stack, the compute engines the data team already uses, and how storage and compute costs behave at projected scale. These are assessments worth working through carefully before commitment, since migration between formats at production scale is expensive.
FAQ: Data Lake, Data Warehouse, and Data Lakehouse
Is a data lakehouse more expensive than a data warehouse?
It depends on the workload mix. A lakehouse separates storage from compute, so you pay for each independently. Storage on open-format systems (S3, Azure Data Lake Storage) is generally cheaper than proprietary warehouse storage. Compute costs depend on query volume, job frequency, and how well the environment is tuned. For organizations running both BI and AI workloads, consolidating them into a lakehouse can reduce total cost by eliminating duplicate data pipelines and the infrastructure that maintains them. For organizations with primarily structured data and predictable query patterns, a well-managed warehouse may still be the more cost-efficient option.
Can a data lake be migrated to a lakehouse without rebuilding everything?
In most cases, yes, with caveats. If the lake already stores data in open formats such as Parquet or ORC, the migration to Delta Lake or Apache Iceberg involves adding metadata layers and transaction log infrastructure rather than moving data files. The heavier lift is usually governance: establishing data catalogs, defining schema contracts, and documenting lineage for data that was previously stored without those controls. Organizations that skipped governance during lake adoption tend to find that migration surfaces those debts rather than eliminating them.
What is the practical difference between ETL and ELT in these architectures?
ETL (extract, transform, load) is the conventional warehouse pattern: data is transformed before it enters the system. ELT (extract, load, transform) is the lake and lakehouse pattern: raw data loads first, and transformation happens downstream at query time or in preparation for a specific use case. ELT is more flexible but requires that the downstream transformation steps are well-managed. If transformation logic is inconsistent across teams, ELT produces multiple conflicting versions of the same data. The lakehouse architecture supports both patterns; the choice should follow from what the data team can maintain reliably.
How does schema-on-read differ from schema-on-write?
Schema-on-write means data must conform to a predefined structure before entering storage. If a record does not match the schema, the load fails. Schema-on-read means data is stored in its original form, and the schema is applied when a query runs. Schema-on-write produces cleaner, more consistent data at the cost of ingestion flexibility. Schema-on-read allows faster ingestion and handles diverse data types, but query results depend on how consistently the schema interpretation is defined and applied. Lakehouses support both: open-format storage with schema-on-write enforcement at the table level, managed through the transaction log.
When does it make sense to run a warehouse and a lake in parallel rather than moving to a lakehouse?
When the two workloads have fundamentally different governance requirements, or when the existing warehouse investment is recent and the BI workloads are well-served by it. Some organizations land raw data in a lake for data science and exploration, maintain a warehouse for finance and regulatory reporting, and adopt lakehouse patterns only for workloads that genuinely benefit from the unified architecture. The right answer is the one the organization can maintain with the team and processes it actually has, not the architecture that looks cleanest on a diagram.
Would you like more information about this topic?
Complete the form below.