- 1. Manufacturing Data: PLC, MES, ERP, and Data Historians as data sources
- 2. IIoT Integration Platform: integrating OT Systems and IT Systems
- 3. Do Point-to-Point Data Integrations Fail at Scale?
- 4. Unified Namespace: Data Models, Data Contracts, and Semantic Alignment
- 5. Event-Driven Architecture: Decoupling and Real-Time Data Integration
- 6. What Does Governance in Data Architecture Actually Require?
- 7. Automation, GitOps, and Pipelines for scalable operations
- 8. AI and Machine Learning; The Role of Data Accessibility and Semantic Alignment
- 9. Cross-Site Analytics; Scaling Insights Across Plants
- 10. When the Foundation Becomes the Constraint
- 11. FAQ
Most factories already have more data than they know what to do with. The bottleneck is architectural. Point-to-point connections accumulate technical debt and fragment data semantics over time, and by the time teams try to scale analytics or deploy machine learning across sites, the foundation isn’t there. Organizations that make progress on this problem tend to share a common approach: a governed IIoT platform built on a Unified Namespace and Event-Driven Architecture, where semantics are standardized, systems are decoupled, and governance is embedded into the architecture rather than added afterward.
Manufacturing analytics projects fail because the data means something different at one plant than it does at another. A PLC status code of “1” at one site signals normal operation. At another, it signals a fault. Both sites are connected, both are logging, both are feeding dashboards. But the datasets can’t be combined without site-specific interpretation that someone has to perform manually, every time a new use case requires it.
That is the architectural problem enterprise IIoT actually needs to solve. Connectivity is table stakes; semantic alignment is the engineering challenge. Most integration programs address the first and assume the second will follow; and it doesn’t.
Manufacturing Data: PLC, MES, ERP, and Data Historians as data sources
Modern factory floors rely on a complex mix of control and enterprise systems, each producing high-frequency operational data in formats that rarely align. Programmable Logic Controllers (PLCs) manage machinery at the equipment level. Manufacturing Execution Systems (MES) track production status and work orders. Enterprise Resource Planning (ERP) systems handle business logic, procurement, and scheduling. Data historians store time-series telemetry continuously, often for years.
On paper, this infrastructure looks substantial. In practice, the manufacturing data it produces reflects the equipment vendor, the local configuration choices made during commissioning, and the project priorities of the team that built each interface. That matters because it determines what is possible when you try to combine data with advanced analytics across systems and sites.
IIoT Integration Platform: integrating OT Systems and IT Systems
Enterprise IT systems expect standardized, consolidated data flows through well-defined interfaces. OT systems produce telemetry shaped by plant-level decisions made years ago. Bridging that divide requires more than a connectivity protocol.
What it requires is a deliberate Factory Integration Layer (FIL): a platform with a clear mandate to ingest data from operational systems, contextualize it early, standardize its meaning, and publish it in a consistent, reusable form. An IIoT Integration Platform built on a hybrid edge-cloud architecture handles connectivity bottlenecks at the plant level while keeping centralized governance intact. Getting that architecture right creates the groundwork for digital solutions that hold up in production, across sites and over time. Most manufacturing environments have built connectivity in some form. A Factory Integration Layer is something more specific and more intentional than that. It is an architectural decision, not an infrastructure upgrade.
Do Point-to-Point Data Integrations Fail at Scale?
Each point-to-point integration decision is defensible in isolation. A system needs data, an interface is built, and when a new reporting requirement appears, another integration is added. The logic is reasonable at the project level. The problem is what accumulates when those decisions are made without a shared model across sites and systems.
Interfaces become tightly coupled. Data structures reflect project history rather than intentional enterprise design. When a new site comes online, the organization rebuilds logic that already exists elsewhere, because there is no shared architecture to inherit. What starts as agility becomes the opposite structural complexity: long lead times, high technical effort, and limited ability to extend the architecture without touching systems that were never designed to change.
Moving away from this pattern requires accelerators that add the standardization and automation that point-to-point builds never included: governed data contracts, consistent topic hierarchies, and centralized deployment logic applied uniformly across sites. Replacing the fragile web of custom interfaces with true IoT Data Integration is what makes the architecture reusable rather than rebuilt from scratch each time.
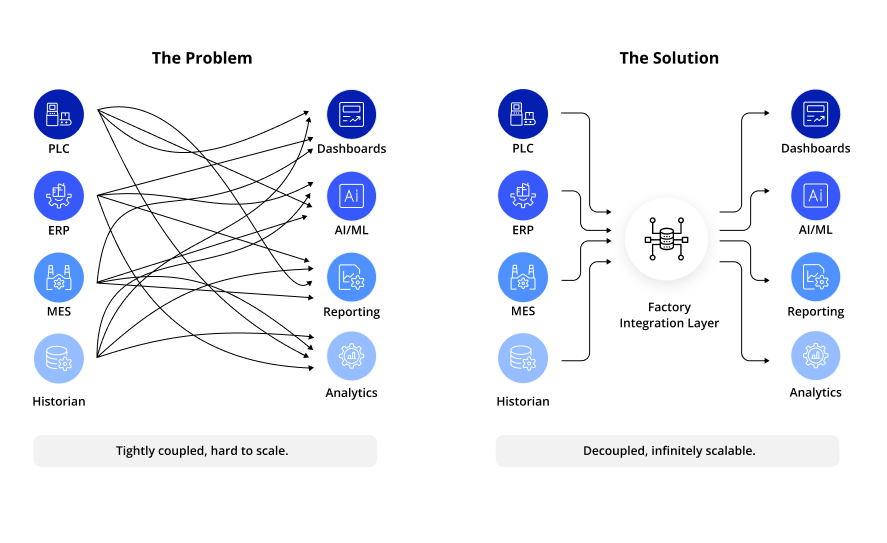
Unified Namespace: Data Models, Data Contracts, and Semantic Alignment
The Unified Namespace concept is frequently reduced to a technology decision: introduce MQTT as a central messaging layer, and the integration problem is solved. This is where most UNS implementations underdeliver.
A UNS without governance is just a messy group chat for your machines. We see it all the time: a company installs an MQTT broker, calls it a ‘Unified Namespace,’ and then wonders why their analytics are still broken. The hard truth? If you don’t enforce a shared asset model from day one, you aren’t solving the problem; you’re just digitizing the chaos.
In a properly governed UNS, data is categorized according with a specific hierarchy. An example of that is the ISA-95 framework provides standardized terminology that bridges enterprise and control systems, defining how assets are represented, how events are named, how schemas evolve, and how changes move through a controlled lifecycle. Standardized data models allow applications to discover data, reuse it across sites, and rely on consistent meaning without local interpretation.
Event-Driven Architecture: Decoupling and Real-Time Data Integration
A governed UNS delivers value only if the underlying interaction model supports decoupling. That is where Event-Driven Architecture (EDA) becomes essential.
In an event-driven model, machines publish events and applications subscribe to them. Producers don’t need to know who consumes their data. This reduces direct dependencies and allows new use cases to be introduced without modifying existing systems. Multiple consumers can reuse the same data stream. Systems can evolve independently.
In manufacturing, this is particularly important because OT systems are long-lived while IT platforms and analytics capabilities change frequently. When interactions are built on Event-Driven Architecture, the system stays adaptable. It prevents complexity from compounding in ways that make the architecture unmaintainable over time.
What Does Governance in Data Architecture Actually Require?
Governance in manufacturing cannot rely solely on documentation and coordination meetings. That approach holds at small scale and breaks down as soon as local changes begin to diverge from the shared model.
At enterprise scale, governance must be embedded into the data architecture itself. Schemas need to be versioned and validated before data is accepted. Topic structures and asset models need to follow defined rules. Standardization at this level is not optional: without it, each site builds its own interpretation layer, and the enterprise ends up with locally coherent data that cannot be combined reliably. Changes should move through a controlled lifecycle with clear ownership at each stage. The ISA-95 hierarchy provides the structural foundation; the UNS governance layer enforces consistent namespace rules and standardization across sites.
In most projects, this governance arrives too late. Teams establish site connections, build initial pipelines, and add governance once the problems become visible. By that point, retrofitting means auditing existing structures, migrating interfaces, and freezing scope while the broader program waits. Building governance in at the start, even in a simplified form covering a single domain or data type, surfaces the structural questions early enough to resolve them before they derail the initiative.
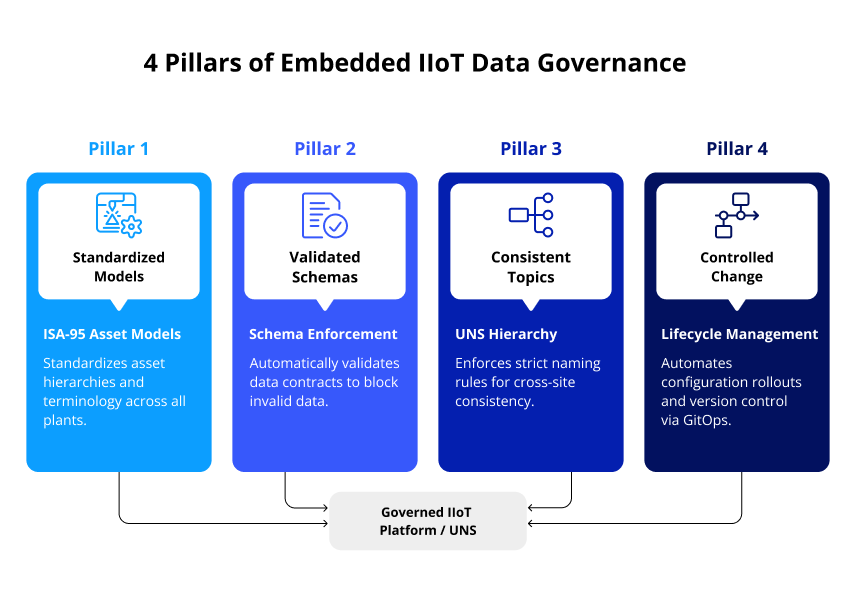
Automation, GitOps, and Pipelines for scalable operations
In multi-site environments, governance also requires a strict execution model. When integration logic is configured independently at each plant, divergence is the default outcome: structures drift, semantics evolve inconsistently, and onboarding each new site becomes a manual exercise that repeats work already done elsewhere.
A GitOps-based approach addresses this by treating integration artifacts as versioned configuration. Data contracts, topic hierarchies, contextualization rules, and pipelines are stored in a central repository. Changes move through a review and validation process before deployment. Site-specific agents apply them consistently. Full recovery in case of disaster is supported by a DevOps pipeline that maintains all configurations centrally.
Governance shifts from a coordination problem to an operational one. Standardization becomes enforced through process rather than agreed in meetings. Observability into how data moves and transforms is built into the deployment model, and traceability of every schema change, routing rule update, and configuration decision is maintained as a permanent audit trail. Structures don’t drift. New sites inherit the existing model rather than building from scratch.
AI and Machine Learning; The Role of Data Accessibility and Semantic Alignment
AI initiatives in manufacturing fail for reasons that have little to do with the models themselves. Data science teams need clean data, consistent meaning, high-frequency access, and unified visibility across sites. What they typically find instead is site-specific formats, unclear data ownership, network segmentation that blocks access, and no unified access layer.
McKinsey’s research on digital manufacturing has linked the inability to scale successful pilots directly to fractured infrastructure and isolated IT implementations. The model works. The data layer doesn’t support it beyond the local context where the pilot was built.
The specific failure mechanism is the semantic gap. Connectivity ensures that data moves; it does not ensure that data means the same thing in every location. Asset structures differ across plants. Status codes follow local conventions. Events are named inconsistently. A pilot succeeds where the team knows the local conventions well enough to work around them. Enterprise rollout stalls because those workarounds don’t travel. To use AI and Machine learning at scale, the data layer must be designed to scale, with consistent semantics across all locations established before the models are deployed.
Cross-Site Analytics; Scaling Insights Across Plants
Cross-site visibility requires shared semantics as a prerequisite, not a post-implementation cleanup. Analytics built on inconsistent data structures produces unreliable results: teams spend more time reconciling site-level differences than generating insight. When data integration becomes a platform rather than a series of disconnected projects, the architecture supports a true data marketplace: telemetry organized within a governed Unified Namespace, accessible across sites while maintaining rigorous security controls.
This shift isn’t just theoretical; it has a profound impact on project timelines. In our experience deploying Unified Namespace organizations typically cut their overall implementation effort by 70% to 95%. Because the structural groundwork is already laid, new sites can plug in and onboard in days rather than months. Instead of rebuilding interpretation logic from scratch for every new use case, teams can immediately start building on top of existing, standardized data.
When the Foundation Becomes the Constraint
The architectural decisions that cause an analytics initiative to stall were usually made two or three projects earlier. That’s the real shape of technical debt in IIoT: the cost arrives when the next initiative needs something the existing architecture can’t provide.
Most teams in that position extend what they have. Another connector, another manually negotiated data contract, another interpretation layer built for the new site. It works for a while, and the pressure to ship something makes the incremental path feel like the responsible one.
The case for a governed UNS, with EDA and a GitOps execution model behind it, comes down to compounding costs. Standardized semantics enforced through architecture rather than coordination means the next site inherits what already works. The next AI project starts with a foundation instead of rebuilding one; that argument tends to land hardest for teams who are already feeling it.
| Architectural Dimension | Traditional Approach (Point-to-Point) | Modern Approach (Governed UNS + EDA) |
| Integration Style | Custom, tightly coupled direct connections. | Decoupled, event-driven (Pub/Sub). |
| Data Semantics | Site-specific. Data requires local interpretation. | Standardized globally (e.g., ISA-95 framework). |
| Governance Model | Manual: Relies on meetings and documentation. | Automated: GitOps-based, embedded in the architecture. |
| Adding a New Site | High effort: Rebuild integration logic from scratch. | Low effort: New sites inherit existing centralized templates. |
| AI & ML Readiness | Blocked by a “semantic gap” and fractured infrastructure. | Scale-ready with unified visibility and consistent data structures. |
FAQ
- We already have a historian and SCADA system collecting data. Do we need a UNS on top of that?
A historian stores time-series telemetry effectively, but it doesn’t address how that data is interpreted by other systems. If your ERP, MES, and analytics tools each connect to the historian through custom interfaces, you are in a point-to-point architecture regardless of how much data the historian holds. The UNS adds a governed layer between sources and consumers, standardizing semantics so downstream applications can rely on consistent meaning across sites. The historian stays; the integration model around it changes.
- How do you govern a UNS when OT and IT teams have different data ownership structures?
This is where most governance frameworks break down. Assigning namespace ownership exclusively to either team creates friction with the other. In practice, OT teams own the asset model and event definitions for their systems; IT teams own the schema registry and change lifecycle. The data contracts that define how data crosses that boundary require agreement from both sides. A GitOps-based deployment model enforces the agreed structure through process, which reduces the ongoing coordination overhead considerably.
- Does Event-Driven Architecture require replacing existing OT systems?
No. Event-Driven Architecture operates at the integration layer, not within the OT systems themselves. Existing PLCs, MES systems, and historians don’t need to change their internal logic. Edge connectors or integration agents handle the translation: they read from existing sources and publish normalized events to the governed UNS. OT systems remain stable; the integration model around them changes.
- At what point does it make sense to start with a UNS, rather than continuing to extend existing integrations?
The clearest signal is when the cost of maintaining existing interfaces exceeds the cost of building a governed alternative. In practice, that threshold tends to arrive when teams are spending more time managing integration exceptions than building new use cases, or when a new AI or analytics initiative stalls because the data foundation isn’t consistent enough to support it. Starting with a single domain or one well-defined data type reduces scope and surfaces the governance questions early, so the organization can understand the constraints before committing to a full platform.
Would you like more information about this topic?
Complete the form below.