
- 1. The Real Problem: Infrastructure Without a Developer Platform
- 2. Signals That Your Data Platform Has This Gap
- 3. The Cost That Data Leaders Shouldn’t Ignore
- 4. From Weeks of Setup to Writing Logic on Day One
- 5. How Scaffolding Affects AI and ML
- 6. Implementing Governance by Design
- 7. When a Data Developer Platform Makes Sense
- 8. Focus on the Friction Teams Already Experience
- 9. A Practical Starting Point
- 10. FAQ
Many organizations have invested heavily in modern data platforms such as Snowflake, Databricks, or cloud-based ecosystems built on Microsoft Azure. These environments provide scalable storage, compute, and orchestration capabilities. On paper, they deliver everything a modern data organization needs.
Yet when a team starts building a new data product, the process often begins the same way: with weeks of setup.
Repositories need to be created. Pipelines have to be wired together. Infrastructure access must be requested. Deployment pipelines need to be configured. By the time these prerequisites are in place, the team may have spent one to three weeks before writing the first line of transformation logic.
The data platform exists, but the developer experience on top of it is often inconsistent or incomplete. This gap between infrastructure and usability is becoming one of the most common sources of friction in growing data organizations.
The Real Problem: Infrastructure Without a Developer Platform
In software engineering, this challenge was addressed years ago through the concept of an Internal Developer Platform (IDP).
Instead of giving teams direct access to raw infrastructure, organizations provide a standardized layer that simplifies how services are created, configured, and deployed. Platforms such as Backstage, Port, and Humanitec provide this capability.
They enable development teams to:
- create new services from standardized templates
- provision infrastructure through self-service workflows
- discover existing services and ownership information
- follow predefined governance and operational guardrails
Data organizations rarely have an equivalent layer.
Most modern data platforms provide the core technical components: compute resources, storage layers, orchestration tools, and analytics capabilities. However, they typically do not define how teams should actually build and operate data products on top of them.
Even integrated platforms like Microsoft Fabric simplify infrastructure management but do not enforce consistent project structures, testing standards, or deployment patterns. Some tools address specific pieces of the puzzle. For example, AWS data.all focuses on provisioning and data sharing. But teams still need to decide how projects are structured, how pipelines are tested, and how deployments are managed.
The result is a common misconception: many organizations assume that implementing a modern data platform automatically creates a productive development environment. In reality, the infrastructure is only the foundation. Without a standardized developer layer on top of it, teams still solve the same setup problems repeatedly.
Signals That Your Data Platform Has This Gap
In larger data organizations, the absence of a developer platform layer usually reveals itself through recurring patterns. These patterns are often accepted as normal operational friction, even though they point to a structural issue.
The “Reference Repository” Template
In many organizations, one team’s repository gradually becomes the unofficial template for new projects. Other teams copy or fork it when starting new work.
Over time this repository accumulates outdated patterns, hardcoded configurations, and assumptions that may no longer apply. Because no single team maintains it as a formal template, every new project inherits technical debt from the start.
The Platform Team as a Request Queue
Platform or infrastructure teams are intended to build reusable capabilities that enable the rest of the organization.
However, when the developer layer is missing, they often spend most of their time responding to operational requests such as:
- provisioning environments
- creating storage resources
- configuring compute clusters
- granting access permissions
Each request may take several days to process. As a result, the platform team becomes a bottleneck instead of a force multiplier.
Governance Tracked Outside the Platform
Another common sign is that governance information lives outside the platform itself. Project metadata, compliance status, and data classifications are frequently maintained in spreadsheets or manually updated documents. Governance teams periodically review projects and record findings, but the information quickly becomes outdated.
When audits or reviews occur, organizations often need to reconstruct an accurate inventory of their data products.
Inconsistent Onboarding for Data Engineers
New engineers often face a steep learning curve when joining the data organization. Without standardized project structures or development conventions, each team works slightly differently. Documentation may be incomplete or outdated, and understanding how systems connect across teams takes time.
As a result, new hires may start committing code relatively quickly but need months before they can confidently navigate the broader data environment.
The Cost That Data Leaders Shouldn’t Ignore
The most visible cost of this gap is engineering time. In many organizations, the setup work for a new data product still requires significant effort from experienced engineers. A typical pattern looks like this: one or two senior engineers, often the tech lead or a senior data engineer, spend two to three weeks configuring project scaffolding, infrastructure connections, and deployment pipelines before development can begin.
If a team delivers three or four data products per year, that can easily translate into six to twelve weeks of senior engineering time spent on setup activities alone.
Now consider a larger organization with ten data teams. At that scale, the combined effort devoted to project setup can reach 60–120 weeks of engineering time annually. In practical terms, this is the equivalent capacity of one or two senior engineers focused almost entirely on solving problems that have already been solved elsewhere in the organization.
However, engineering time is only the most visible cost. The structural effects are often more significant.
Inconsistent Quality Across Data Products
When teams lack standardized development patterns, each project evolves differently. Decisions about testing, data validation, documentation, and deployment practices are made independently by each team.
Some teams implement comprehensive validation checks and automated testing. Others rely on minimal safeguards. Documentation quality also varies widely: some data products include clear lineage, ownership, and service-level expectations, while others depend on informal knowledge within the team. Without shared infrastructure and templates, this variation becomes inevitable.
Governance Overhead
When every project is structured differently, governance processes tend to become manual. Architecture or compliance teams may attempt to review projects before they reach production, checking for classification policies, documentation completeness, or access control rules. In practice, this approach rarely scales well. It introduces bottlenecks while still leaving room for inconsistencies.
The alternative, setting governance standards without enforcing them technically, doesn’t look good either. It often results in guidelines that are difficult to follow and therefore inconsistently applied.
Increasing Complexity Over Time
The longer organizations operate without standardization, the more difficult it becomes to introduce it later.
Every new project created with a different structure, naming convention, or deployment pattern adds to the complexity of the ecosystem. Eventually, organizations find themselves facing large remediation efforts just to establish consistent practices across existing data products. Addressing the problem early helps avoid this compounding effect.
From Weeks of Setup to Writing Logic on Day One
To understand the difference a developer platform layer can make, it helps to compare the typical experience of starting a new data product today with what a more standardized approach could look like.
The Typical Experience
Consider a data engineer tasked with building a new customer churn dataset for the commercial analytics team. The process often starts with a blank repository. The engineer needs to determine which conventions apply: how projects should be structured, which pipeline templates exist, how deployments are handled, and which testing standards should be used. Answers are often scattered across Slack conversations, outdated documentation, or examples from other teams’ repositories.
Next comes infrastructure setup. CI/CD pipelines need to be configured, service connections established, and permissions granted. Access requests for compute and storage resources may require multiple tickets and manual approvals. Only after these steps are completed, sometimes one or two weeks later, can the engineer begin implementing transformation logic and delivering business value.
A More Standardized Approach
Organizations that introduce a developer platform layer can significantly simplify this process. Instead of starting from scratch, engineers begin in a platform portal and create a new data product using a predefined blueprint. The blueprint defines a recommended structure and includes the infrastructure, tooling, and guardrails needed to support development.
For example, an engineer might choose a blueprint for a project based on dbt running on Databricks. During creation, the platform collects a small set of required metadata such as domain ownership, data classification, and service expectations. Once the request is submitted, the platform automatically prepares the project environment.
Within minutes, the engineer receives:
- a repository generated with the organization’s recommended project structure
- preconfigured CI/CD pipelines with testing and quality checks
- provisioned compute and storage resources with appropriate access policies
- an entry in the organization’s data catalog with ownership metadata and lineage placeholders
- monitoring dashboards ready to track pipeline performance
At that point, the engineer can immediately clone the repository, connect to the environment, and begin implementing transformation logic.
The key difference is that infrastructure decisions are encoded once and reused consistently. Instead of solving the same setup challenges repeatedly, teams can focus on the business logic that creates value from data.
This shift, from weeks of setup work to productive development on the first day, can significantly improve both engineering efficiency and the overall developer experience within a data organization.
How Scaffolding Affects AI and ML
Many organizations are currently under pressure to operationalize artificial intelligence. However, the infrastructure challenges discussed earlier tend to be even more complex for AI and machine learning projects than for traditional analytics workloads.
Building an ML solution involves significantly more operational components than a typical data pipeline. A production-ready environment may include:
- model training infrastructure
- experiment tracking systems
- feature engineering pipelines
- model registries
- deployment and serving mechanisms
- monitoring for model drift and performance degradation
Without standardized infrastructure, each ML team often builds its own version of this stack. One team may rely on MLflow for experiment tracking and model management. Another might adopt Weights & Biases because they are unaware of existing internal standards. A third team might implement custom tooling to address gaps they encounter.
Over time, this leads to fragmented practices across the organization. Model deployment approaches differ. Governance processes vary. Monitoring and rollback strategies are inconsistent. As a result, many organizations report that they are “doing AI,” but struggle to consistently move models from experimentation into reliable production systems.
A developer platform approach can help address this challenge. Instead of expecting each team to assemble its own ML infrastructure, organizations can provide standardized blueprints for common ML workflows.
For example, a blueprint for a new ML project could automatically provision:
- an experiment tracking workspace
- connections to the organization’s feature store
- a model registry entry
- training environments with appropriate cost controls
- deployment pipelines with integrated monitoring
This does not remove flexibility. Teams can still deviate from the standard when necessary. However, the default path becomes significantly easier than building everything from scratch.
In practice, this kind of operational foundation often makes the difference between organizations that experiment with AI and those that can reliably deliver AI-powered products at scale.
Implementing Governance by Design
Another important benefit of a standardized developer platform is its impact on governance. Traditionally, governance in data organizations relies heavily on manual review processes. Before projects move to production, a central team may examine them for compliance with standards such as:
- data classification policies
- access control rules
- documentation requirements
- testing and validation practices
While this approach can work in smaller environments, it becomes difficult to scale as the number of projects grows. Review processes introduce delays, create friction between delivery teams and governance functions, and still leave room for inconsistencies. A platform-based approach enables a different model: governance by design.
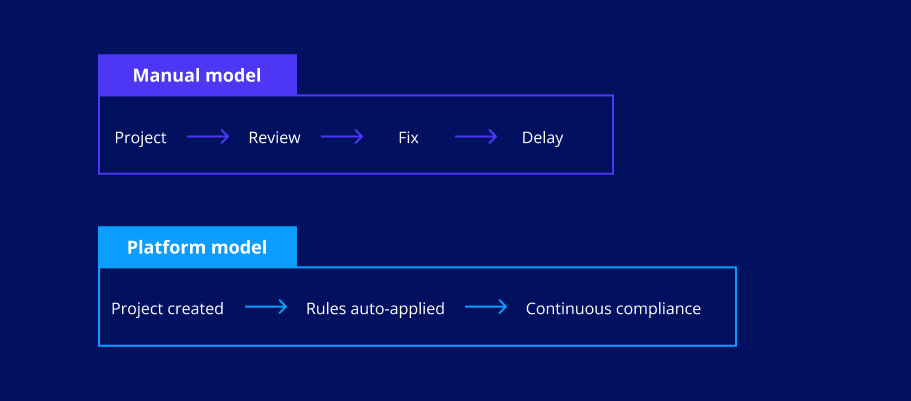
When projects are created using standardized templates or blueprints, many governance requirements can be embedded directly into the development workflow.
For example:
Data classification can be enforced at creation time.
Blueprints can require teams to specify the classification level of a dataset when a project is created. Based on that classification, the platform automatically applies appropriate access controls, encryption policies, and retention rules.
Quality gates can be built into every pipeline.
CI/CD pipelines generated by the platform can include baseline checks such as schema validation, data quality tests, and linting rules. Teams may extend these checks for their own needs, but the minimum standard is always applied.
Documentation and lineage can be generated automatically.
Standard project structures can produce documentation artifacts as part of normal development workflows. Data catalogs and lineage tools can be updated automatically rather than relying on manual documentation efforts.
Audit trails become part of the platform.
When projects are created through a platform workflow, key information is captured automatically: when the project was created, which blueprint version was used, which metadata was provided, and what approvals were required.
This approach changes the nature of governance discussions. Instead of asking how to manually review every project, organizations can focus on encoding standards into the platform itself, so that compliance becomes the default state rather than a separate process.
When a Data Developer Platform Makes Sense
While the benefits of a developer platform layer can be significant, it is not the right investment for every organization. Smaller teams often solve these challenges effectively through simpler mechanisms. If a data organization has fewer than ten engineers and only delivers a limited number of data products each year, introducing a full developer platform may create unnecessary overhead.
In these environments, a well-maintained project template, clear documentation, and consistent code review practices can often address most of the setup challenges described earlier.
The value of a developer platform becomes clearer as organizations scale. When multiple teams build different types of data products: analytics pipelines, machine learning models, streaming workflows, maintaining consistency through informal coordination becomes increasingly difficult.
At that point, standardizing the development experience through shared blueprints and automated provisioning can significantly reduce friction across teams. A useful diagnostic question is simple: are multiple teams independently solving the same infrastructure problems?
If the answer is yes, the organization likely has a platform problem rather than a documentation problem.
Focus on the Friction Teams Already Experience
Introducing a developer platform is not only a technical initiative. It is also an organizational change that affects how teams work. For this reason, successful adoption usually starts by addressing problems that delivery teams already recognize. Proposing a new “internal developer platform” may not resonate with many stakeholders. In contrast, framing the initiative around concrete improvements: such as reducing project setup time from weeks to a single day, makes the value much clearer.
It is also important to treat the platform as a product rather than a one-time project. Platform teams should approach internal data teams as their customers: gathering feedback, refining templates, and continuously improving the development experience.
In practice, the most effective approach is to begin with a small scope. Rather than attempting to support every possible project type from the beginning, organizations can start by standardizing the most common pattern: for example, a batch analytics pipeline built with dbt. Once a small number of teams begin using a shared blueprint, feedback can guide further improvements and expansion to additional workloads such as machine learning pipelines or streaming data products.
Another important factor is adoption. If the platform is positioned primarily as a governance initiative, teams may see it as an additional compliance burden. If it improves their daily development experience, adoption tends to follow naturally—and governance improvements become a by-product.
Finally, the ownership model should be defined early. A developer platform requires ongoing investment and maintenance. This responsibility may sit with a dedicated data platform engineering team, a centralized data organization, or a platform-focused center of excellence. What matters most is that the platform has clear ownership and long-term support.
A Practical Starting Point
Organizations interested in exploring this approach can start with a simple exercise. Identify the most common type of data product your teams build, for example, an analytics pipeline or reporting dataset. Then talk to several teams that recently created one of these projects and ask a straightforward question: what steps were required before development could begin?
The answers usually include tasks such as:
- creating and configuring a new repository
- setting up CI/CD pipelines
- requesting access to compute and storage resources
- configuring monitoring or logging
- defining project structure and conventions
Documenting these steps provides a clear picture of where time is being spent before any business logic is written. That list is effectively the blueprint for the first standardized project template.
Not every step can be automated immediately. However, even partial automation can significantly reduce the setup effort required for new projects. Over time, additional capabilities can be incorporated into the platform as teams identify further opportunities for standardization.
In many organizations, simply mapping these setup steps is enough to reveal how much friction exists in the current development process and to start a conversation about how a better developer experience could improve the way data teams deliver value.
FAQ
Do we need a data developer platform if we already have templates or a reference repository?
Templates and reference repositories are a starting point, but they are usually static and manually maintained. A developer platform operationalizes these patterns. It automates provisioning, enforces standards, integrates governance, and ensures that templates stay up to date. Without automation and ownership, templates tend to drift and accumulate technical debt.
When does investing in a developer platform make sense?
It becomes valuable when multiple teams are building data products and repeatedly solving the same setup problems. If you see engineers spending weeks configuring environments, or platform teams acting as a request queue, it is a strong signal. Smaller teams can often manage with simpler approaches, but complexity grows quickly with scale.
Will a standardized data platform limit team flexibility?
Not necessarily. A good platform provides a default path that is easy and efficient, while still allowing teams to deviate when needed. The goal is not to remove flexibility, but to make the common case simple and consistent.
What impact does a developer platform have on AI and machine learning projects?
It can significantly reduce fragmentation and setup complexity. By providing standardized blueprints for ML workflows, organizations can ensure consistent practices for experiment tracking, model deployment, and monitoring. This makes it easier to move from experimentation to reliable production systems.
Would you like more information about this topic?
Complete the form below.